虚拟文件系统
VFS主要支持三种文件类型:
- 磁盘文件系统:比如ext4、ext3等,这种文件系统起到磁盘的作用。可以联想windows的NTFS系统。
- 网络文件系统:NFS,可以允许从网络中读取文件
- 特殊文件系统:比如proc用于保存进程,FIFO保存管道,这种文件不管理硬盘空间
VFS的目的是引出一个通用文件模型,本质上,Linux内核在访问文件系统都是使用函数指针进行操作,通常我们将文件系统看作是oop的。
普通文件模型中最基本的就是超级块对象,超级块就是系统的循环链表中的一个节点对象,它定义在linux/fs.h内:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| struct super_block {
struct list_head s_list;
dev_t s_dev;
unsigned char s_blocksize_bits;
unsigned long s_blocksize;
loff_t s_maxbytes;
struct file_system_type *s_type;
unsigned long s_flags;
unsigned long s_iflags;
unsigned long s_magic;
struct dentry *s_root;
struct rw_semaphore s_umount;
int s_count;
atomic_t s_active;
struct hlist_bl_head s_roots;
struct list_head s_mounts;
struct block_device *s_bdev;
void *s_fs_info;
time64_t s_time_min;
time64_t s_time_max;
char s_id[32];
uuid_t s_uuid;
atomic_long_t s_remove_count;
struct user_namespace *s_user_ns;
struct mutex s_sync_lock;
int s_stack_depth;
spinlock_t s_inode_list_lock ____cacheline_aligned_in_smp;
struct list_head s_inodes;
} __randomize_layout;
|
第二个就是索引节点对象,依然保存在fs.h内,主要用于保存文件的属性信息,例如文件大小或者文件标识符等:
inode有两种,一种是VFS的inode,一种是具体文件系统的inode。前者在内存中,后者在磁盘中。所以每次其实是将磁盘中的inode调进填充内存中的inode,这样才是算使用了磁盘文件inode,同时inode号是唯一的,表示不同的文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| struct inode {
umode_t i_mode;
unsigned short i_opflags;
kuid_t i_uid;
kgid_t i_gid;
unsigned int i_flags;
const struct inode_operations *i_op;
struct super_block *i_sb;
struct address_space *i_mapping;
union {
const unsigned int i_nlink;
unsigned int __i_nlink;
};
dev_t i_rdev;
loff_t i_size;
spinlock_t i_lock;
u8 i_blkbits;
atomic64_t i_version;
atomic64_t i_sequence;
atomic_t i_count;
atomic_t i_dio_count;
atomic_t i_writecount;
union {
const struct file_operations *i_fop;
void (*free_inode)(struct inode *);
};
struct file_lock_context *i_flctx;
struct address_space i_data;
struct list_head i_devices;
union {
struct pipe_inode_info *i_pipe;
struct cdev *i_cdev;
char *i_link;
unsigned i_dir_seq;
};
void *i_private;
} __randomize_layout;
|
第三个是目录结构,负责描述文件的逻辑属性,VFS将它当作一个文件看待,他也是路径的组成部分之一,它只存在于内存中,存在的意义是提升文件索引的能力,最主要的就是文件夹也属于目录结构,这些目录结构构成了一颗庞大的树。目录结构对应的结构体是dentry,他定义在linux/dcache.h内
目录也是inode,也有对应的编号
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| struct dentry {
unsigned int d_flags;
seqcount_spinlock_t d_seq;
struct hlist_bl_node d_hash;
struct dentry *d_parent;
struct qstr d_name;
struct inode *d_inode;
unsigned char d_iname[DNAME_INLINE_LEN];
struct lockref d_lockref;
const struct dentry_operations *d_op;
struct super_block *d_sb;
unsigned long d_time;
void *d_fsdata;
union {
struct list_head d_lru;
wait_queue_head_t *d_wait;
};
struct list_head d_child;
struct list_head d_subdirs;
union {
struct hlist_node d_alias;
struct hlist_bl_node d_in_lookup_hash;
struct rcu_head d_rcu;
} d_u;
} __randomize_layout;
|
最后就是最基础的文件对象,因为一个文件可以被多个进程打开,所以文件对象不唯一,但是inode唯一。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| struct file {
union {
struct llist_node f_llist;
struct rcu_head f_rcuhead;
unsigned int f_iocb_flags;
};
struct path f_path;
struct inode *f_inode;
const struct file_operations *f_op;
spinlock_t f_lock;
atomic_long_t f_count;
unsigned int f_flags;
fmode_t f_mode;
struct mutex f_pos_lock;
loff_t f_pos;
struct fown_struct f_owner;
const struct cred *f_cred;
struct file_ra_state f_ra;
u64 f_version;
void *private_data;
struct address_space *f_mapping;
errseq_t f_wb_err;
errseq_t f_sb_err;
} __randomize_layout
__attribute__((aligned(4)));
|
我们发现,每一个结构体都有相似的属性比如f_flags、f_model等,这些是文件的控制信息,如果多进程读取文件可以保护文件内容。
从结构上看我们从大到小依次介绍了一遍,从结构上看,File是最基本的对象,这些对象有对应的dentry进行分类管理,而这些文件都有inode,它们被超级块(super_block)管理。
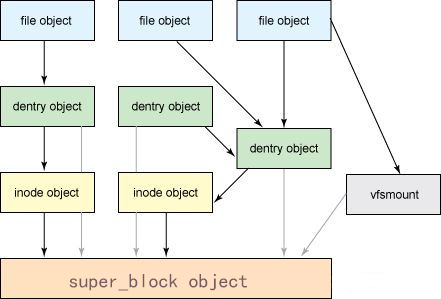
所以我们知道了在linux系统中,真正管理对象的是inode而不是文件属性,文件属性只是供人使用的内容。我们使用指令ls -li就可以获取当前目录下所有文件的信息,其中第一列对应的就是inode编号,其余的就是file属性包括读写属性,所有用户、文件大小、创建日期和文件名。
1
2
3
4
5
6
7
8
| minloha@minloha:~$ ls -li
total 20
135106 drwxrwxrwx 2 root root 4096 Dec 23 00:44 boot
135389 drwxrwxrwx 2 root root 4096 Dec 23 15:17 c
123030 drwxrwxrwx 12 minloha minloha 4096 Dec 22 21:57 glib-2.45.2
810 drwxrwxrwx 26 root root 4096 Dec 23 00:22 linux
122595 drwxrwxrwx 4 minloha minloha 4096 Dec 22 21:53 pkg-config-0.29.2
minloha@minloha:~$
|
因为文件的inode是唯一的,这样我们就明白了ln 进行的文件链接的具体链接的是什么了:
硬链接就是生成一个指向原文件lnode的指针,操作指针的同时也操作了原文件,相当于是文件的别名。不过inode是对应的超级块进行分配的,一旦跨文件系统,inode不唯一时,硬链接就无法链接了。如果这个时候删除了源文件,硬链接是不会消失的,因为inode链接数仍然大于1,VFS会将他识别为一个有效的文件。
软链接就是一个保存了目标文件的路径和文件名的逻辑信息文件,是会被重新赋予inode编号的,所以源文件删除后,软链接文件就失去了目标,自然无法发挥作用。
Linux最先启动的文件系统就是根目录,因为很多内核代码保存在根目录内,这样的话也方便其余文件能够挂在到根目录上,形成完整的文件结构。
关于根文件系统的挂载阶段有三部分:
- 第一部分:挂在rootfs,提供“/”路径
- 加载initrd,续接VFS树
- 执行init,完成初始化,将文件系统的根从rootfs切换到磁盘文件系统
在init/main.c内描述了启动的过程:
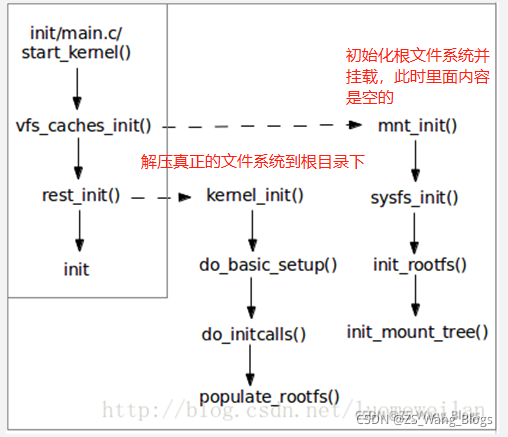
据图分析,在高速缓存阶段已经初始化了磁盘、系统、根、文件树文件系统,按照这个次序就可以建立一个初始化目录的哈希表,内核可以设置最大的打开数,同时大大提高了查找效率。同时因为构造的目录保存在缓存中,在之后的使用会更快捷。
mnt_init()和sysfs_init()负责初始化结构,而init_rootfs负责挂载根目录,同时注册根文件系统。
完成了目录初始化之后,为了提高效率,内核制定了两种数据结构:
- 正在使用和未使用的目录项
- 包含了可以快速获取文件名于目录名对应的散列表
进程也有自己的工作目录,也包含在VFS内,每个进程都使用fs_struct结构保存,他定义在linux/fs_struct.h下:
1
2
3
4
5
6
7
8
9
10
11
12
| struct fs_struct {
int users;
spinlock_t lock;
seqcount_spinlock_t seq;
int umask;
int in_exec;
struct path root, pwd;
} __randomize_layout;
|
这就是进程描述符的fs指向的结构。files_struct是为了记录进程打开的文件而使用的结构体,他定义在linux/fdtable.h下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| struct files_struct {
atomic_t count;
bool resize_in_progress;
wait_queue_head_t resize_wait;
struct fdtable __rcu *fdt;
struct fdtable fdtab;
spinlock_t file_lock ____cacheline_aligned_in_smp;
unsigned int next_fd;
unsigned long close_on_exec_init[1];
unsigned long open_fds_init[1];
unsigned long full_fds_bits_init[1];
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};
|
我们发现缓存保存的fd_array使用大小为NR_OPEN_DEFAULT,它的大小区间是32~64,所以多出来的文件需要有新的存储空间,内核会根据情况对fd_array进行扩容。而进行扩容管理的结构体定义在linux/fdtable.h内:
1
2
3
4
5
6
7
8
9
10
| struct fdtable {
unsigned int max_fds;
struct file __rcu **fd;
unsigned long *close_on_exec;
unsigned long *open_fds;
unsigned long *full_fds_bits;
struct rcu_head rcu;
};
|
这里有一些特殊的文件系统举例,VFS需要对所有的文件系统类型进行跟踪,所以每个文件系统都需要进行注册,注册使用file_system_type对象表示。
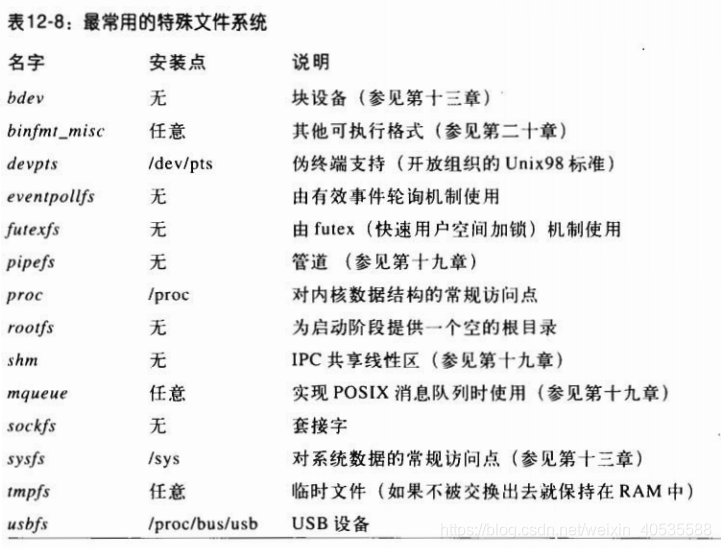
图片摘自:https://zhuanlan.zhihu.com/p/482045070
所有文件系统都插入为file_systems的元素
file_systems_lock 读/写自旋锁保护整个链表免受同时访问。
file_system_type 的一些字段:
fs_supers,表示给定类型的已安装文件系统所对应的超级块链表的头。
链表元素的向后和向前链接存放在超级块对象的 s_instances 字段。
get_sb,指向依赖于文件系统类型的函数,该函数分配一个新的超级块对象并初始化它。
kill_sb,指向删除超级块的函数。
fs_flags,存放几个标志。
在系统初始化器间,register_filesystem() 注册编译时指定的每个文件系统:
该函数把相应的 file_system_type 对象插入到文件系统类型的链表。
当文件系统的模块被装入时,也要调用 register_filesystem()。
当该模块被卸载时,对应的文件系统也可以被注销。
get_fs_type() 扫描已注册的文件系统链表以查找文件系统类型的 name 字段,并返回指向相应的 file_system_type 对象的指针。
我们还记得之前所说的一切内容皆文件吧,下面看看进程在VFS内的体现。内核通过命名空间抽象资源,同时分离为各个不同的容器使得彼此之间相互隔离,但同时耶提供了一些可以交互的接口。
创建一个这样的命名空间有两种方式:
- 使用fork或clone创建子进程时可控制是否共用命名空间
- 可以分离某部分变成新的命名空间
在linux/nsproxy.h内定义了子进程命名空间的指针,每个进程都有一个这样的命名空间。
1
2
3
4
5
6
7
8
9
10
11
12
13
| struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns_for_children;
struct net *net_ns;
struct time_namespace *time_ns;
struct time_namespace *time_ns_for_children;
struct cgroup_namespace *cgroup_ns;
};
|
下面详细描述一下这些命名空间的具体含义,请看变量名:
- uts:隔离用户
- ipc:应用于进程通讯,当于PID空间组合起来的时候,同一个IPC空间的进程可以与彼此通信
- mnt:每个进程都包含一个这样的命名空间,它提供了一个文件层次,如果父进程不设定,那么子进程可能会影响到所有这样的进程。
- pid:进程号管理,他是进程的唯一标志,且仅父空间看到子空间的pid号
- net:为进程提供了网络协议,包括Socket套接字等等,它负责提供网络环境
- time: 时钟空间,主要负责处理中断时间时或者进程调度时进行切换
- cgroup:Linux内核的控制空间,可以控制和管理子系统
卸载文件系统主要按照下列步骤
- 查找文件系统的挂在路径,保存查询结果
- 如果目标没有在命名空间内,则跳到最后一步
- 如果没有权限删除文件系统,则跳到最后一步
- 条件都满足,则:
- 找到文件系统的超级块,停止文件系统的所有工作
- 挂在mutex锁,保护命名空间
- 释放文件系统内的各种对象。
- 释放自旋锁,释放命名空间
- 减少计数值和文件描述符的值,返回结束值
这部分的结束介绍一下文件锁,类似与多线程,文件锁也有互斥锁和自旋锁,不过名字不一样,这里进行一下联想记忆:
- 写入锁(互斥锁):只能由一个进程调用文件
- 强制性锁(自旋锁):进程读取后自动加锁,防止读取错误
- 建议性锁(使用时为互斥锁):如果出现多个疑似进程调用文件时,自动保护
RAM到ROM的缓存
我们知道了SRAM到DRAM的缓存是cache,他是一种分级管理的缓存塔,主要由CPU进行控制,而如果需要将硬盘上保存的内容读取到内存上,Linux内核就使用了一种页高速缓存的方法,它的核心结构体是address_space,它嵌入在页的索引节点中,同时可以组建多个这样的页为一个表,进行方便的管理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| struct address_space {
struct inode *host;
struct radix_tree_root page_tree;
rwlock_t tree_lock;
unsigned int i_mmap_writable;
struct prio_tree_root i_mmap;
struct list_head i_mmap_nonlinear;
spinlock_t i_mmap_lock;
unsigned int truncate_count;
unsigned long nrpages;
pgoff_t writeback_index;
struct address_space_operations *a_ops;
unsigned long flags;
struct backing_dev_info *backing_dev_info;
spinlock_t private_lock;
struct list_head private_list;
struct address_space *assoc_mapping;
} __attribute__((aligned(sizeof(long))));
|
为了方便查找,每个address_space对象都有一棵搜索树,它包含指向所有者的页描述符的指针。当查找所需要的页时,内核把页索引转换为基数树中的路径,并快速找到页描述符所在的位置。如果找到,内核可从基数树获得页描述符,并很快确定所找的页是否为脏页,以及其数据的 I/O 传送是否正值进行。
address_space有这么多方法:
基数树可以有64个指针指向radix_tree_node节点,它定义在linux/radix-tree.h下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| struct radix_tree_node {
unsigned int height;
unsigned int count;
union {
struct radix_tree_node *parent;
struct rcu_head rcu_head;
};
void __rcu *slots[RADIX_TREE_MAP_SIZE];
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS];
};
struct radix_tree_root {
unsigned int height;
gfp_t gfp_mask;
struct radix_tree_node __rcu *rnode;
}
|
当数据从ROM读取之后都会保存在这样的基数树内,这样的缓冲区也叫page cache,其中缓冲区的顶部就是buffer head,页块缓冲与都是页,buffer head包含了块设备的设备信息、编号、位置、偏移量等。
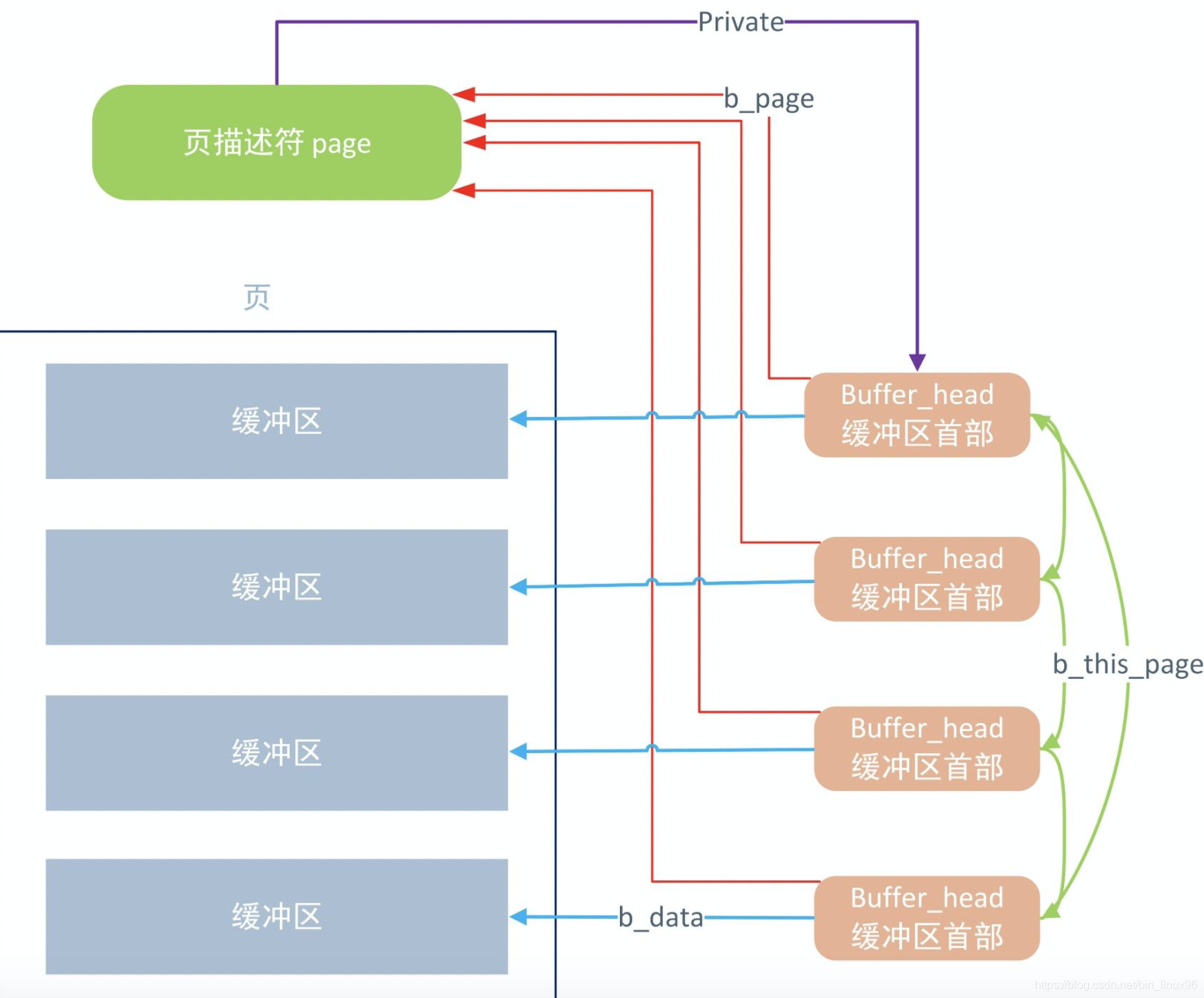
从宏观的角度看缓冲区是这样的。 从硬盘读取到的内容就会保存在这些缓冲区页内,不过随着写入量的增加就会产生一些脏页。
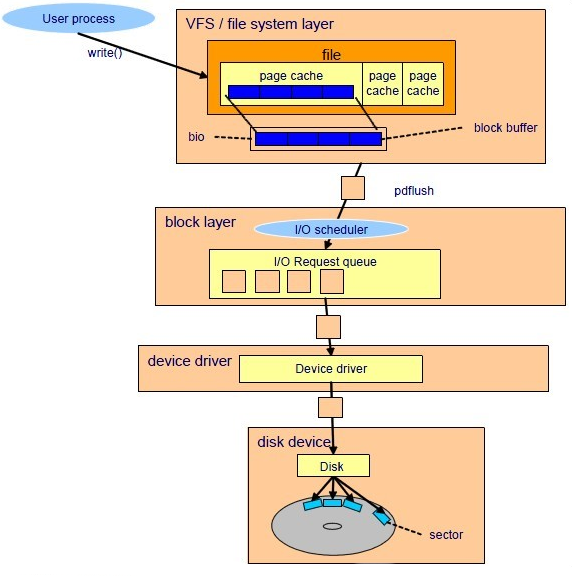
当缓冲区写满后,页面就变成了脏页,这是就需要将数据重新写入到硬盘内,如果不进行保存,脏页太多就会倒是内存不够用。这里有脏页的处理办法。
- sync():允许进程把所有脏缓冲区刷新到磁盘。
- fsync():允许进程把属于特定打开文件的所有块刷新到磁盘。
- fdatasync():与 fsync() 相似,但不刷新文件的索引节点块。
内核时允许对缓冲区进行IO操作的,所以缓冲区建立好后就会发起bio操作,就是同步操作,负责从硬盘中同步读或写操作,然后将内容保存到缓存中。这样内核就可以更快速的获取到数据。