内存管理
内存管理主要包含分页管理,伙伴算法、SLAB内存分配器,以及几种内存分配器的分配机制。
分页管理
Linux内存使用分页管理机制,在mm_types.h定义了针对不同分页管理的结构,通过整合发现,每一个union体内都包含了最基本的元素:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| struct page {
unsigned long flags;
union {
struct {
union {
struct list_head lru;
struct {
void *__filler;
unsigned int mlock_count;
};
struct list_head buddy_list;
struct list_head pcp_list;
};
struct address_space *mapping;
pgoff_t index;
unsigned long private;
};
struct {
unsigned long pp_magic;
struct page_pool *pp;
unsigned long _pp_mapping_pad;
unsigned long dma_addr;
union {
unsigned long dma_addr_upper;
atomic_long_t pp_frag_count;
};
};
};
} _struct_page_alignment;
|
我们首先知道page是管理内存页,并不是虚拟的,内存页仅提供给内核一个信息,在内核运行后,描述内存的页也就不存在了。内核必须使用这一结构进行管理内存,每一个页都有这样的结构体,这些结构体占总内存的比例很小,所以可以忽略。
为了内存管理,内核首先会对内存进行分类,一部分可以直接读取使用,一部分正常使用,一部分用于高位映射:
- ZONE_DMA 内存开始的16MB
- ZONE_NORMAL 16MB~896MB
- ZONE_HIGHMEM 896MB ~ 结束
从固定位置开始可以方便管理用户代码,便于检查空指针。因为建立了分页,程序再想访问内存时就需要访问分页函数,从线性地址获取到位置的使用情况,然后根据情况进行映射。同时为了防止误伤内核运行,Linux内核运行在ZONE_NORMAL区域上。
CPU的位数也决定了可以除了多少内存地址,根据CPU一次可以处理的内存大小可以使用其寻址,如果一个64位的CPU,它可以处理2^64位的地址。这样64位系统可以同时管理很大的内存空间
当永久内存映射临时内存映射非连续内存时,就可以让内存分出一块空间,借用这段空间建立一个填充内核表PTE内存表。这样就可以访问所有的内存空间了。
Q:内核可以访问多大的内存?
A:全部内存
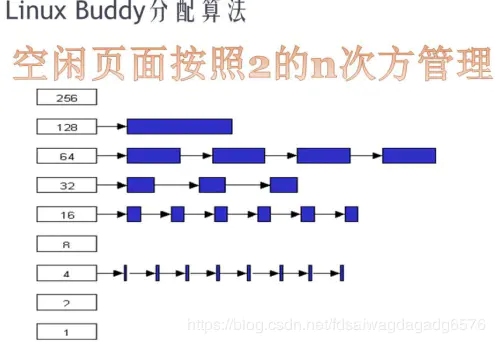
伙伴算法
这种算法负责分配内存空间,为了避免malloc生成内存空间碎片,所以不能完全实现malloc算法,所谓内存碎片指内存被分割很多细小的不连续的内存块,这些块在使用时越分越小,最后内存全剩下碎片而无法使用。
伙伴算法首先将内存划分为空间指数增长的链表区域,如果需要一块内存空间,就需要在链表内遍历出一个合适的大小,然后进行分配,如果在相近的地方没有发现满足条件的内存区域或者内存空间不足,就需要继续向下申请,将下一个内存空间对半平分用作上一个空间的后继。
简而言之就是搜索一个被申请内存要大的内存空间,如果存在则直接使用,如果不存在,则去平分更大的空间,一部分给程序,另一部分用作下次分配。
这里我举一个例子(参考自https://blog.csdn.net/wenqian1991/article/details/27968779)
假设系统中有 1MB 大小的内存需要动态管理,按照伙伴算法的要求:需要将这1M大小的内存进行划分。这里,我们将这1M的内存分为 64K、64K、128K、256K、和512K 共五个部分,如下图 a 所示
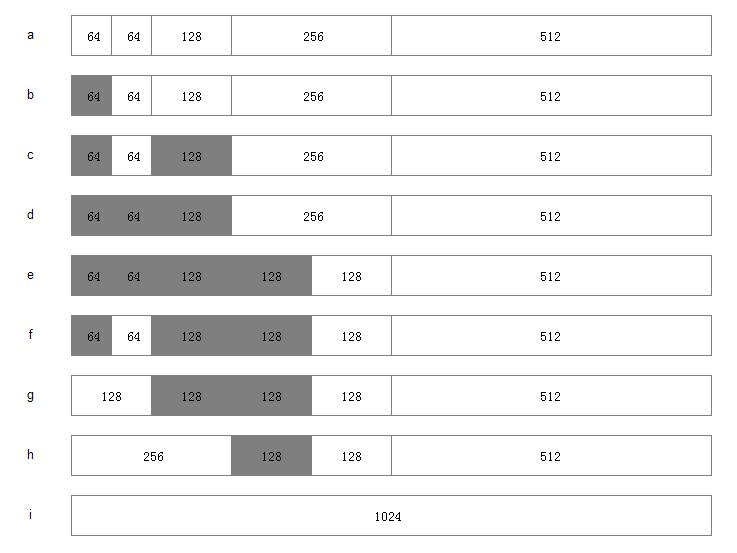
1.此时,如果有一个程序A想要申请一块45K大小的内存,则系统会将第一块64K的内存块分配给该程序(产生内部碎片为代价),如图b所示;
2.然后程序B向系统申请一块68K大小的内存,系统会将128K内存分配给该程序,如图c所示;
3.接下来,程序C要申请一块大小为35K的内存。系统将空闲的64K内存分配给该程序,如图d所示;
4.之后程序D需要一块大小为90K的内存。当程序提出申请时,系统本该分配给程序D一块128K大小的内存,但此时内存中已经没有空闲的128K内存块了,于是根据伙伴算法的原理,系统会将256K大小的内存块平分,将其中一块分配给程序D,另一块作为空闲内存块保留,等待以后使用,如图e所示;
5.紧接着,程序C释放了它申请的64K内存。在内存释放的同时,系统还负责检查与之相邻并且同样大小的内存是否也空闲,由于此时程序A并没有释放它的内存,所以系统只会将程序C的64K内存回收,如图f所示;
6.然后程序A也释放掉由它申请的64K内存,系统随机发现与之相邻且大小相同的一段内存块恰好也处于空闲状态。于是,将两者合并成128K内存,如图g所示;
7.之后程序B释放掉它的128k,系统也将这块内存与相邻的128K内存合并成256K的空闲内存,如图h所示;
8.最后程序D也释放掉它的内存,经过三次合并后,系统得到了一块1024K的完整内存,如图i所示。
在linux/mmzone.h内定义了zone管理算法最基本的结构体。从链表结构我们就可以发现伙伴算法适合管理大块的内存空间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
struct zone {
atomic_long_t managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
int initialized;
struct free_area free_area[MAX_ORDER];
unsigned long flags;
} ____cacheline_internodealigned_in_smp;
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
|
SLAB
如果需要管理小块的内存空间,就不能使用分页管理了,这是可以使用SLAB分配器,这是一种基于对象进行管理的,这种单元在有需要是分配,释放时统一回收,避免内存碎片,同时在分配内存也会优先分配常用的内存块,这样可以弥补内存管理颗粒度太大的问题。
在C语言中使用结构体进行oop,而SLAB使用oop的思想去管理内存空间,Linux最基本的内存单元是mm_struct,为了这类高频使用的对象读取速度更快,Slab会创建一个cache这样可以快速的处理分页。这个cache的结构体叫kmem_cache,写在slab_def.h内
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| struct kmem_cache {
struct array_cache __percpu *cpu_cache;
unsigned int batchcount;
unsigned int limit;
unsigned int shared;
unsigned int size;
struct reciprocal_value reciprocal_buffer_size;
slab_flags_t flags;
unsigned int num;
unsigned int gfporder;
size_t colour;
unsigned int colour_off;
unsigned int freelist_size;
const char *name;
struct list_head list;
int refcount;
int object_size;
int align;
unsigned int useroffset;
unsigned int usersize;
struct kmem_cache_node *node[MAX_NUMNODES];
};
|
这里有一个关于slab管理方式的图,首先描述了一个带有三个kmem_cache节点的缓存链表,每个链表包含一个slab列表,每个列表包含一个连续的内存空间,slab有三个状态:完全分配,不完全分配,空对象,每个内存分页都可以自由移动。
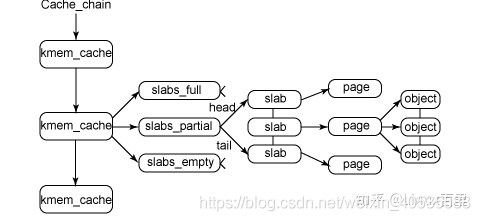
高速缓存氛围两种类型,一种是slab使用的叫做普通高速缓存,另一种是用于分配的,使用kmalloc分配。
1
2
3
4
5
6
7
8
9
10
11
12
|
static __always_inline __alloc_size(1) void *kmalloc(size_t size, gfp_t flags){
if (__builtin_constant_p(size)) {
if (size > KMALLOC_MAX_CACHE_SIZE)
return kmalloc_large(size, flags);
index = kmalloc_index(size);
}
return __kmalloc(size, flags);
}
|
slab的最小分配内存为32字节,并且这种分配器依赖于buddy系统,我们访问linux/slab.h,内部定义了很多slab的接口。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
struct kmem_cache *kmem_cache_create(const char *name, unsigned int size,
unsigned int align, slab_flags_t flags,
void (*ctor)(void *));
struct kmem_cache *kmem_cache_create_usercopy(const char *name,
unsigned int size, unsigned int align,
slab_flags_t flags,
unsigned int useroffset, unsigned int usersize,
void (*ctor)(void *));
void kmem_cache_destroy(struct kmem_cache *s);
int kmem_cache_shrink(struct kmem_cache *s);
void *kmem_cache_alloc(struct kmem_cache *s, gfp_t flags) __assume_slab_alignment __malloc;
void kmem_cache_free(struct kmem_cache *s, void *objp);
|
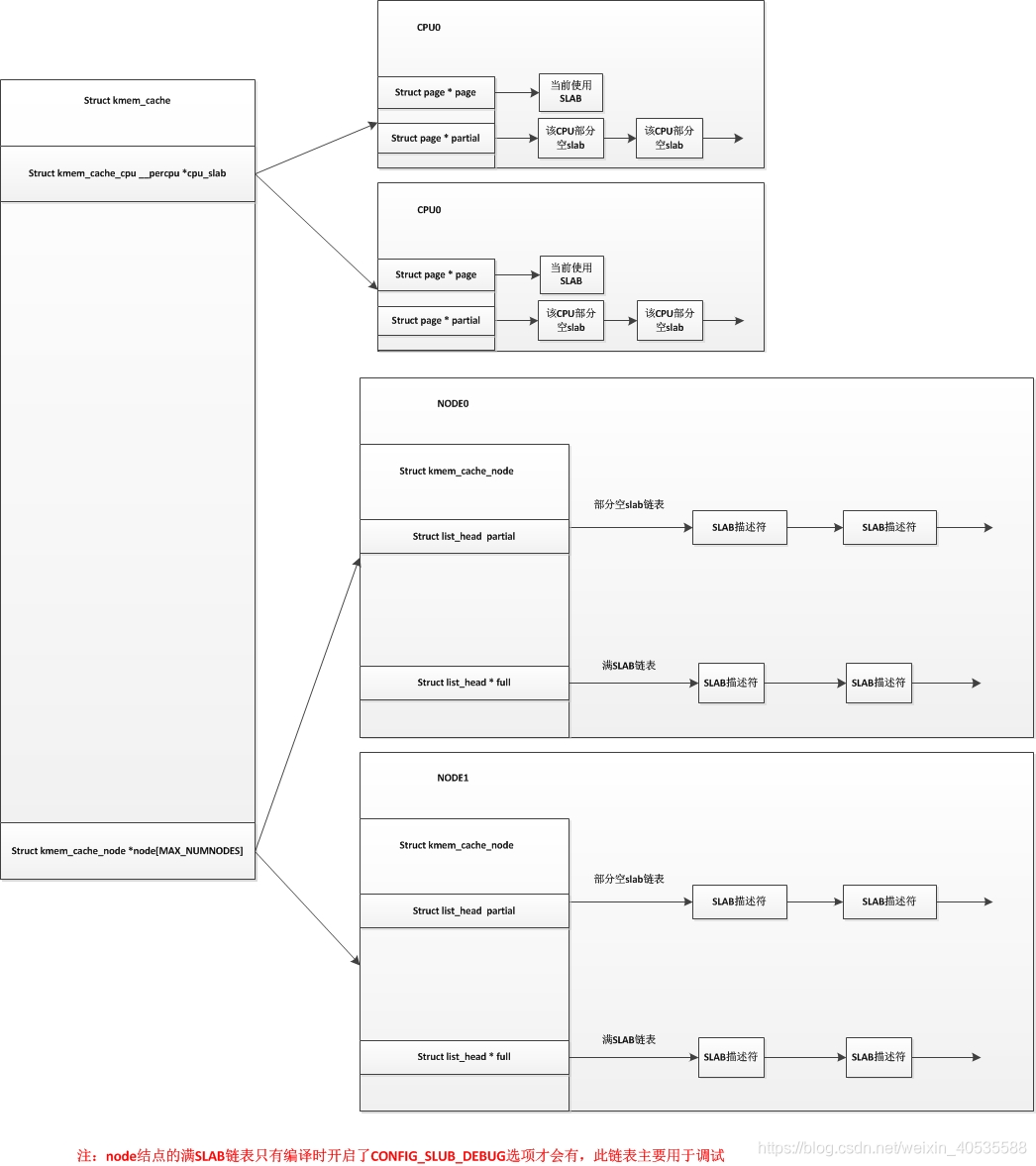
当然小内存分配器一共有三种,SLAB,SLOB,SLUB,slob主要应用于嵌入式系统。slub将cache的三个链表简化为一个链表。
非连续内存地址
我们还记得,线性地址可以映射到物理地址,映射关系保存在虚拟地址空间内。
- 直接映射区:线性地址和物理地址直接建立关系
- 内存映射区:使用vmalloc分配,线性空间连续但物理地址可能不连续
- 固定映射区:地址有特殊用途
- 永久映射区:访问高位内存空间。
kmalloc、vmalloc和malloc区别:
- kmalloc和vmalloc分给内核内存空间,malloc分给用户内存空间
- kmalloc分配的是物理连续主要是cache,vmalloc是虚拟空间连续
- vmalloc和malloc能分配的空间较大,但是速度慢于kmalloc
- 需要进行DMA访问时才需要物理地址连续(因为不需要CPU介入)
更深入关于内存管理的可以看看这篇博文,总结的比较到位https://www.jianshu.com/p/a563a5565705
进程空间
进程一般指系统正在运行的程序,或者程序实例,这种运行中的序列或者遗传指令就叫做进程。进程是代码运行的活动单元,是一个状态的集合体,它具有以下属性:标识符(PID)、状态(Status)、优先级(Priority)、计数器(Count)、指针(Pointer)、数据(Data)、IO信息。
我们介绍过内存地址的类型,包含物理内存地址,虚拟内存地址和线性内存地址,对于线性内存地址需要使用线性描述符,它定义为vm_area_struct
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| struct vm_area_struct{
unsigned long vm_start;
unsigned long vm_end;
struct vm_area_struct *vm_next;
pgprot_t vm_page_prot;
unsigned long vm_flags;
short vm_avl_height;
struct vm_area_struct * vm_avl_left;
struct vm_area_struct * vm_avl_right;
struct file * vm_file;
unsigned long vm_raend;
void * vm_private_data;
}
|
用户进程也需要使用内存空间,这部分内存空间是虚拟地址空间,也叫做进程空间,对于进程,所有内容都在内存描述符内,这里包含了所有信息,包括PID、活跃状态,这个结构体叫mm_struct。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
| struct mm_struct {
struct {
struct maple_tree mm_mt;
#ifdef CONFIG_MMU
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
#endif
unsigned long mmap_base;
unsigned long mmap_legacy_base;
#ifdef CONFIG_HAVE_ARCH_COMPAT_MMAP_BASES
unsigned long mmap_compat_base;
unsigned long mmap_compat_legacy_base;
#endif
unsigned long task_size;
pgd_t * pgd;
#ifdef CONFIG_MEMBARRIER
atomic_t membarrier_state;
#endif
atomic_t mm_users;
atomic_t mm_count;
#ifdef CONFIG_MMU
atomic_long_t pgtables_bytes;
#endif
int map_count;
spinlock_t page_table_lock;
struct rw_semaphore mmap_lock;
struct list_head mmlist;
unsigned long hiwater_rss;
unsigned long hiwater_vm;
unsigned long total_vm;
unsigned long locked_vm;
atomic64_t pinned_vm;
unsigned long data_vm;
unsigned long exec_vm;
unsigned long stack_vm;
unsigned long def_flags;
seqcount_t write_protect_seq;
spinlock_t arg_lock;
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long saved_auxv[AT_VECTOR_SIZE];
struct mm_rss_stat rss_stat;
struct linux_binfmt *binfmt;
mm_context_t context;
unsigned long flags;
#ifdef CONFIG_AIO
spinlock_t ioctx_lock;
struct kioctx_table __rcu *ioctx_table;
#endif
#ifdef CONFIG_MEMCG
struct task_struct __rcu *owner;
#endif
struct user_namespace *user_ns;
struct file __rcu *exe_file;
#ifdef CONFIG_MMU_NOTIFIER
struct mmu_notifier_subscriptions *notifier_subscriptions;
#endif
#if defined(CONFIG_TRANSPARENT_HUGEPAGE) && !USE_SPLIT_PMD_PTLOCKS
pgtable_t pmd_huge_pte;
#endif
#ifdef CONFIG_NUMA_BALANCING
unsigned long numa_next_scan;
int numa_scan_seq;
#endif
atomic_t tlb_flush_pending;
#ifdef CONFIG_ARCH_WANT_BATCHED_UNMAP_TLB_FLUSH
atomic_t tlb_flush_batched;
#endif
struct uprobes_state uprobes_state;
#ifdef CONFIG_PREEMPT_RT
struct rcu_head delayed_drop;
#endif
#ifdef CONFIG_HUGETLB_PAGE
atomic_long_t hugetlb_usage;
#endif
struct work_struct async_put_work;
#ifdef CONFIG_IOMMU_SVA
u32 pasid;
#endif
#ifdef CONFIG_KSM
unsigned long ksm_merging_pages;
unsigned long ksm_rmap_items;
#endif
#ifdef CONFIG_LRU_GEN
struct {
struct list_head list;
unsigned long bitmap;
#ifdef CONFIG_MEMCG
struct mem_cgroup *memcg;
#endif
} lru_gen;
#endif
} __randomize_layout;
unsigned long cpu_bitmap[];
};
|
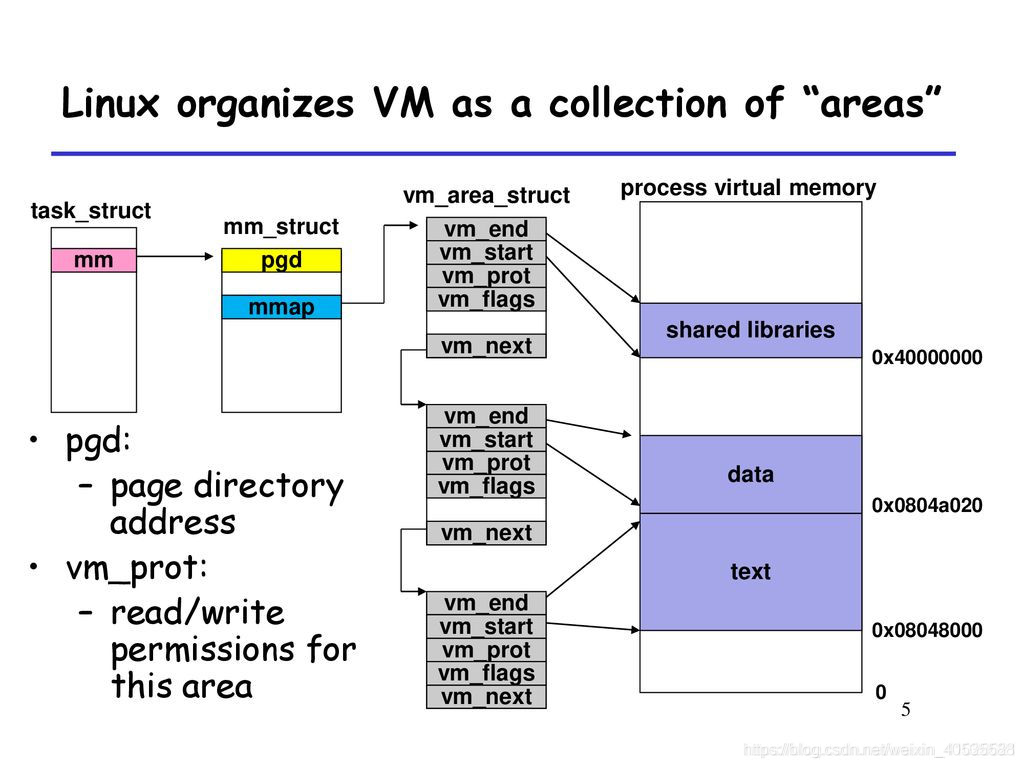
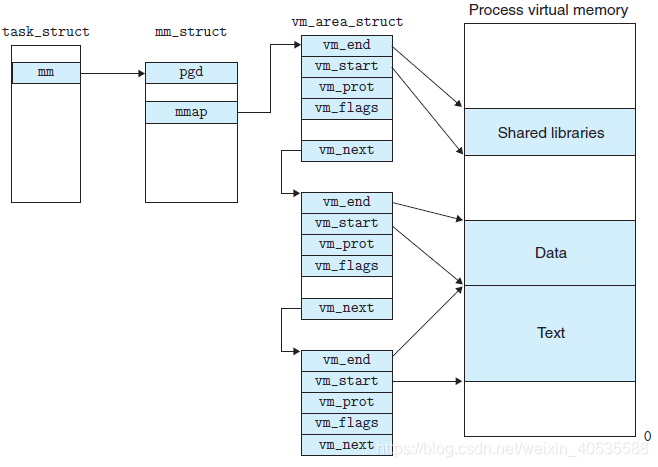
mm_struct描述了整个进程的虚拟空间,包括虚拟空间自身的属性。系统进程使用进程描述符task_struct描述,它定义在linux/sched.h中,下面是进程描述符的定义。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| struct task_struct {
const cpumask_t *cpus_ptr;
cpumask_t *user_cpus_ptr;
cpumask_t cpus_mask;
int exit_state;
int exit_code;
int exit_signal;
int pdeath_signal;
struct task_struct __rcu *real_parent;
struct task_struct __rcu *parent;
struct list_head children;
struct list_head sibling;
struct task_struct *group_leader;
struct pid *thread_pid;
struct hlist_node pid_links[PIDTYPE_MAX];
struct list_head thread_group;
struct list_head thread_node;
struct completion *vfork_done;
int __user *set_child_tid;
int __user *clear_child_tid;
void *worker_private;
u64 utime;
u64 stime;
struct signal_struct *signal;
struct sighand_struct __rcu *sighand;
struct syscall_user_dispatch syscall_dispatch;
raw_spinlock_t pi_lock;
struct wake_q_node wake_q;
struct thread_struct thread;
};
|
这三个内存结构体的关系如图,最根本的管理层次是task_struct。
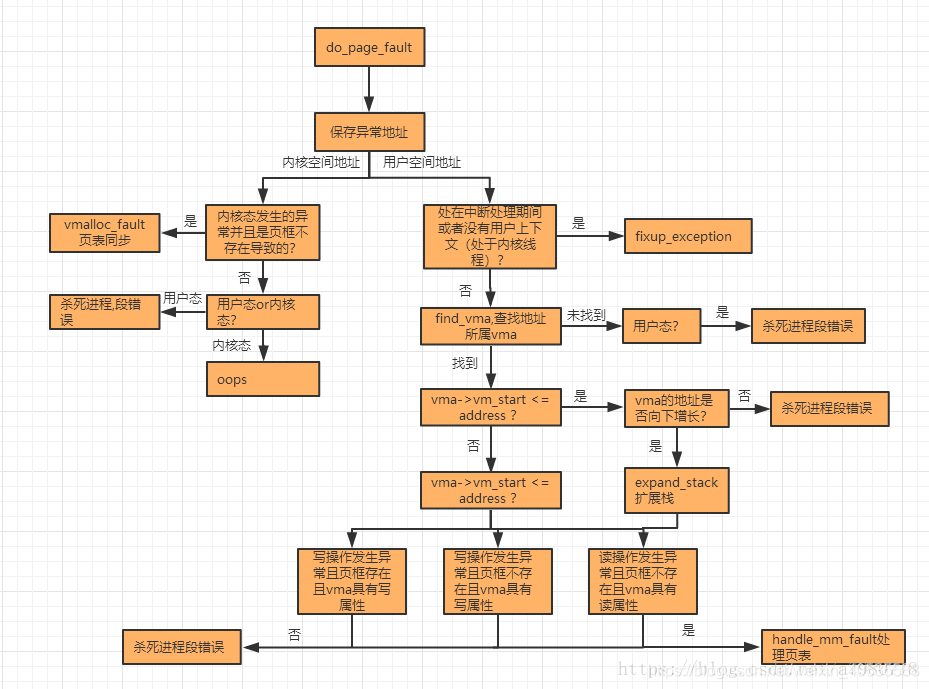
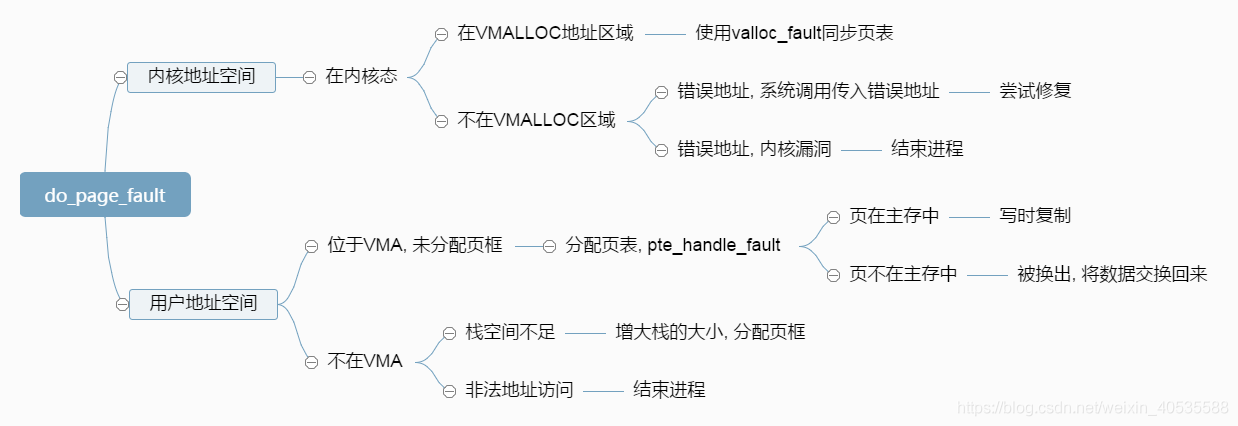
最后介绍以下如果虚拟页缺失的处理方法,页面丢失有三种情况,分别为:
- 访问不存在的地址
- 访问地址超过页面空间
- 访问地址不存在映射关系
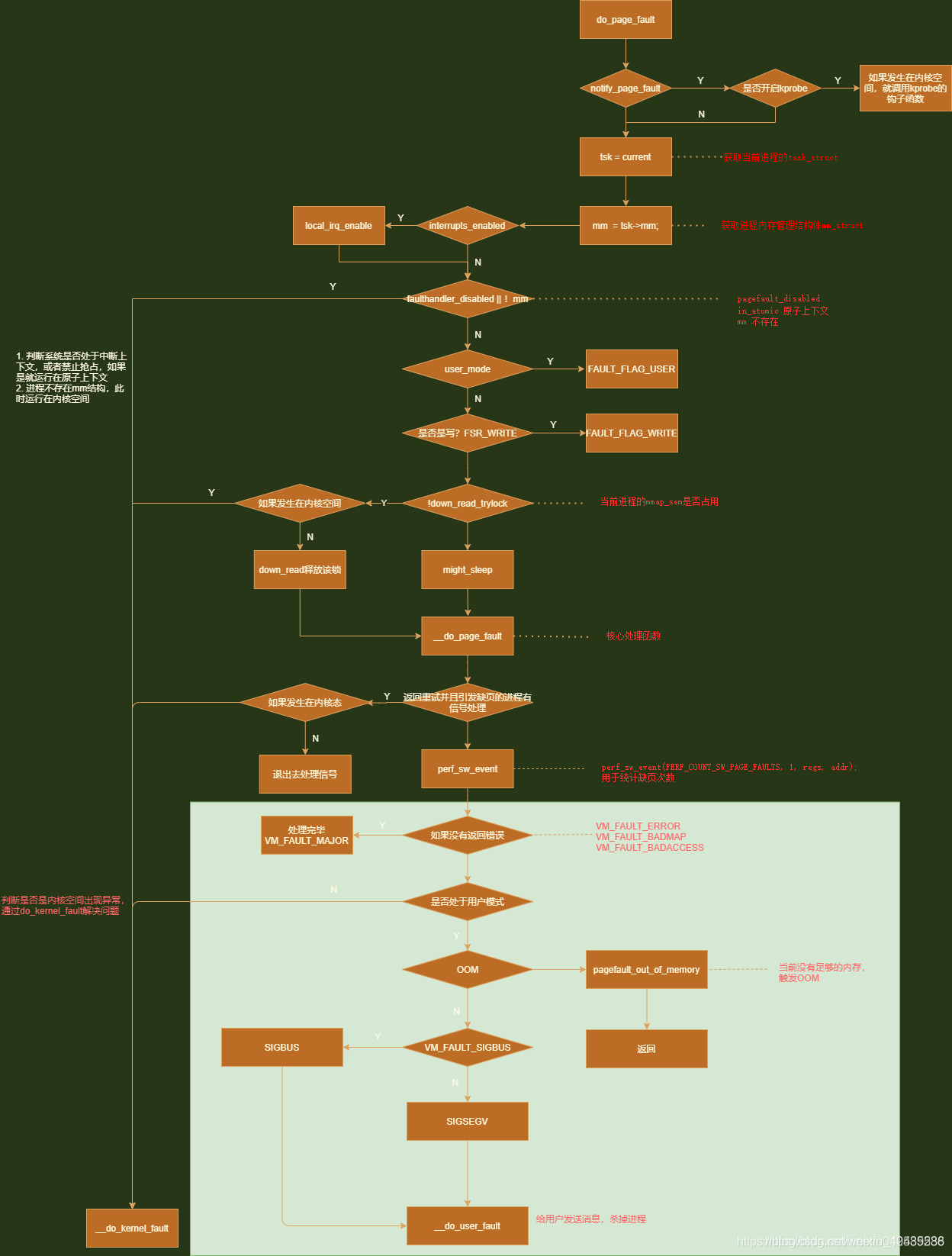
当触发上述情况就会触发Linux的NVIC表(中断表)进行判断缺失情况。这里使用方法_do_page_fault(),它定义在arch/arm/mm/fault.c内。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
|
static vm_fault_t __kprobes
__do_page_fault(struct mm_struct *mm, unsigned long addr, unsigned int flags,
unsigned long vma_flags, struct pt_regs *regs)
{
struct vm_area_struct *vma = find_vma(mm, addr);
if (unlikely(!vma))
return VM_FAULT_BADMAP;
if (unlikely(vma->vm_start > addr)) {
if (!(vma->vm_flags & VM_GROWSDOWN))
return VM_FAULT_BADMAP;
if (addr < FIRST_USER_ADDRESS)
return VM_FAULT_BADMAP;
if (expand_stack(vma, addr))
return VM_FAULT_BADMAP;
}
if (!(vma->vm_flags & vma_flags))
return VM_FAULT_BADACCESS;
return handle_mm_fault(vma, addr & PAGE_MASK, flags, regs);
}
static int __kprobes
do_page_fault(unsigned long addr, unsigned int fsr, struct pt_regs *regs)
{
struct mm_struct *mm = current->mm;
int sig, code;
vm_fault_t fault;
unsigned int flags = FAULT_FLAG_DEFAULT;
unsigned long vm_flags = VM_ACCESS_FLAGS;
if (kprobe_page_fault(regs, fsr))
return 0;
if (interrupts_enabled(regs))
local_irq_enable();
if (faulthandler_disabled() || !mm)
goto no_context;
if (user_mode(regs))
flags |= FAULT_FLAG_USER;
if (is_write_fault(fsr)) {
flags |= FAULT_FLAG_WRITE;
vm_flags = VM_WRITE;
}
if (fsr & FSR_LNX_PF) {
vm_flags = VM_EXEC;
if (is_permission_fault(fsr) && !user_mode(regs))
die_kernel_fault("execution of memory",
mm, addr, fsr, regs);
}
perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS, 1, regs, addr);
if (!mmap_read_trylock(mm)) {
if (!user_mode(regs) && !search_exception_tables(regs->ARM_pc))
goto no_context;
retry:
mmap_read_lock(mm);
} else {
might_sleep();
}
fault = __do_page_fault(mm, addr, flags, vm_flags, regs);
if (fault_signal_pending(fault, regs)) {
if (!user_mode(regs))
goto no_context;
return 0;
}
if (fault & VM_FAULT_COMPLETED)
return 0;
if (!(fault & VM_FAULT_ERROR)) {
if (fault & VM_FAULT_RETRY) {
flags |= FAULT_FLAG_TRIED;
goto retry;
}
}
mmap_read_unlock(mm);
if (likely(!(fault & (VM_FAULT_ERROR | VM_FAULT_BADMAP | VM_FAULT_BADACCESS))))
return 0;
if (!user_mode(regs))
goto no_context;
if (fault & VM_FAULT_OOM) {
pagefault_out_of_memory();
return 0;
}
if (fault & VM_FAULT_SIGBUS) {
sig = SIGBUS;
code = BUS_ADRERR;
} else {
sig = SIGSEGV;
code = fault == VM_FAULT_BADACCESS ?
SEGV_ACCERR : SEGV_MAPERR;
}
__do_user_fault(addr, fsr, sig, code, regs);
return 0;
no_context:
__do_kernel_fault(mm, addr, fsr, regs);
return 0;
}
|
执行流程见下图(图源自https://blog.csdn.net/weixin_40535588/article/details/119671436)
实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| #ifndef AGT_SCHAR_H
#define AGT_SCHAR_H
#include <string.h>
#include <malloc.h>
#include <stdio.h>
typedef struct
__attribute((packed)) _SChar{
int length;
int free;
char *value;
} schar;
schar* init(char* text,int free);
int getLength(schar* s);
schar* strappend(schar* s,char* text);
void freeSChar(schar* s);
void showSChar(schar* s);
#endif
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| #include "include/schar.h"
schar* init(char* text,int free){
schar* s = (schar*)malloc(sizeof(schar));
s->value = (char*)malloc(strlen(text) + free);
s->value = text;
s->length = strlen(text);
s->free = free;
return s;
}
int getLength(schar* s){
return s->length;
}
schar* strappend(schar* s,char* text){
if(s->free > strlen(text)) {
strcat(s->value, text);
s->length += strlen(text);
s->free -= strlen(text);
}else{
char* aim = (char*) malloc(s->length + strlen(text) + s->free);
memcpy(aim,s->value,s->length);
strcat(aim,text);
s->value = aim;
s->length += strlen(text);
s->free = 4;
}
return s;
}
void freeSChar(schar* s){
free(s->value);
free(s);
}
void showSChar(schar* s){
for(int m =0;m<s->length;m++){
printf("%c",s->value[m]);
}
printf("\n");
}
|
总结
本期博文主要讲了Linux的内存类型和内存管理方式,在使用C语言开发时,编译器并不会提供一个非常完美的内存回收机制,比如JVM的GC一样。所以要求C程序员做好内存管理,防止被内存泄漏。
Linux的内存管理主要包含了分页管理和伙伴算法两种,其余的皆为分配器,分配器可以帮助分页管理时更有条理。下一期讲进程和Linux的VFS。
第二期:>点我跳转/)
第一期:>点我跳转/)