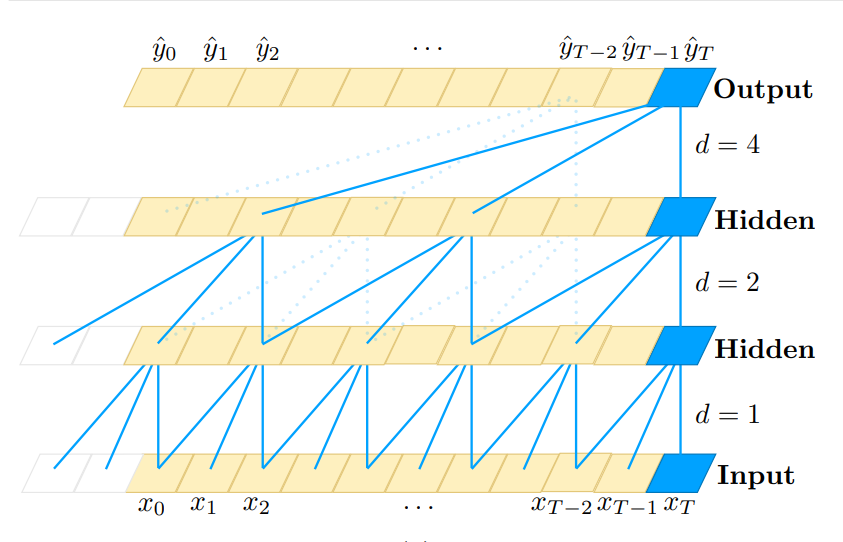
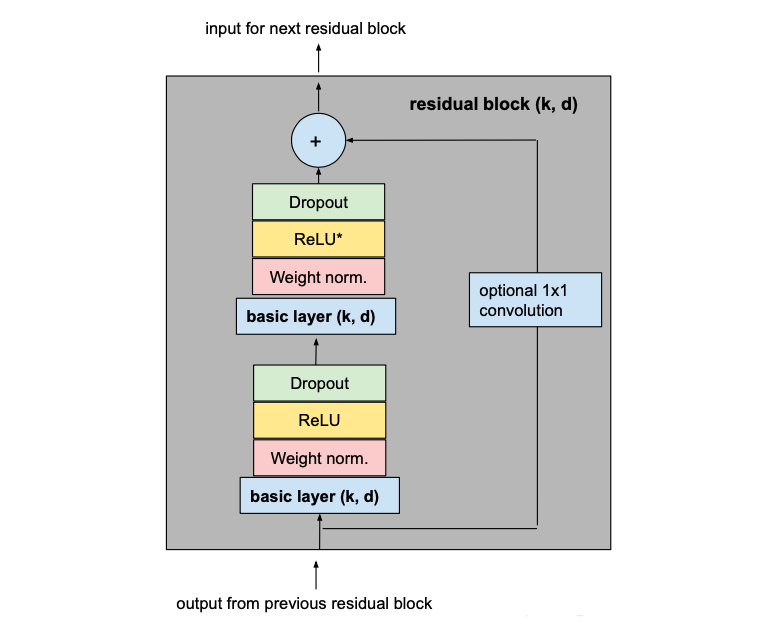
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| epoch 970, loss 0.0169, test acc 0.000, time 0.0 sec
epoch 971, loss 0.0169, test acc 0.000, time 0.0 sec
epoch 972, loss 0.0169, test acc 0.000, time 0.0 sec
epoch 973, loss 0.0169, test acc 0.000, time 0.0 sec
epoch 974, loss 0.0169, test acc 0.000, time 0.0 sec
epoch 975, loss 0.0169, test acc 0.000, time 0.0 sec
epoch 976, loss 0.0169, test acc 0.000, time 0.0 sec
epoch 977, loss 0.0169, test acc 0.000, time 0.0 sec
epoch 978, loss 0.0168, test acc 0.000, time 0.0 sec
epoch 979, loss 0.0168, test acc 0.000, time 0.0 sec
epoch 980, loss 0.0168, test acc 0.000, time 0.0 sec
epoch 981, loss 0.0168, test acc 0.000, time 0.0 sec
epoch 982, loss 0.0168, test acc 0.000, time 0.0 sec
epoch 983, loss 0.0168, test acc 0.000, time 0.0 sec
epoch 984, loss 0.0168, test acc 0.000, time 0.0 sec
epoch 985, loss 0.0168, test acc 0.000, time 0.0 sec
epoch 986, loss 0.0167, test acc 0.000, time 0.0 sec
epoch 987, loss 0.0167, test acc 0.000, time 0.0 sec
epoch 988, loss 0.0167, test acc 0.000, time 0.0 sec
epoch 989, loss 0.0167, test acc 0.000, time 0.0 sec
epoch 990, loss 0.0167, test acc 0.000, time 0.0 sec
epoch 991, loss 0.0167, test acc 0.000, time 0.0 sec
epoch 992, loss 0.0167, test acc 0.000, time 0.0 sec
epoch 993, loss 0.0167, test acc 0.000, time 0.0 sec
epoch 994, loss 0.0167, test acc 0.000, time 0.0 sec
epoch 995, loss 0.0166, test acc 0.000, time 0.0 sec
epoch 996, loss 0.0166, test acc 0.000, time 0.0 sec
epoch 997, loss 0.0166, test acc 0.000, time 0.0 sec
epoch 998, loss 0.0166, test acc 0.000, time 0.0 sec
epoch 999, loss 0.0166, test acc 0.000, time 0.0 sec
epoch 1000, loss 0.0166, test acc 0.000, time 0.0 sec
|