Seq2Seq与Transformer
复习RNN
在之前的博文里,为了方便大家理解RNN,我把它画成了前馈的结构,就像下图一样,我们接下来就需要将他换一种表达结构,也就是序列结构。
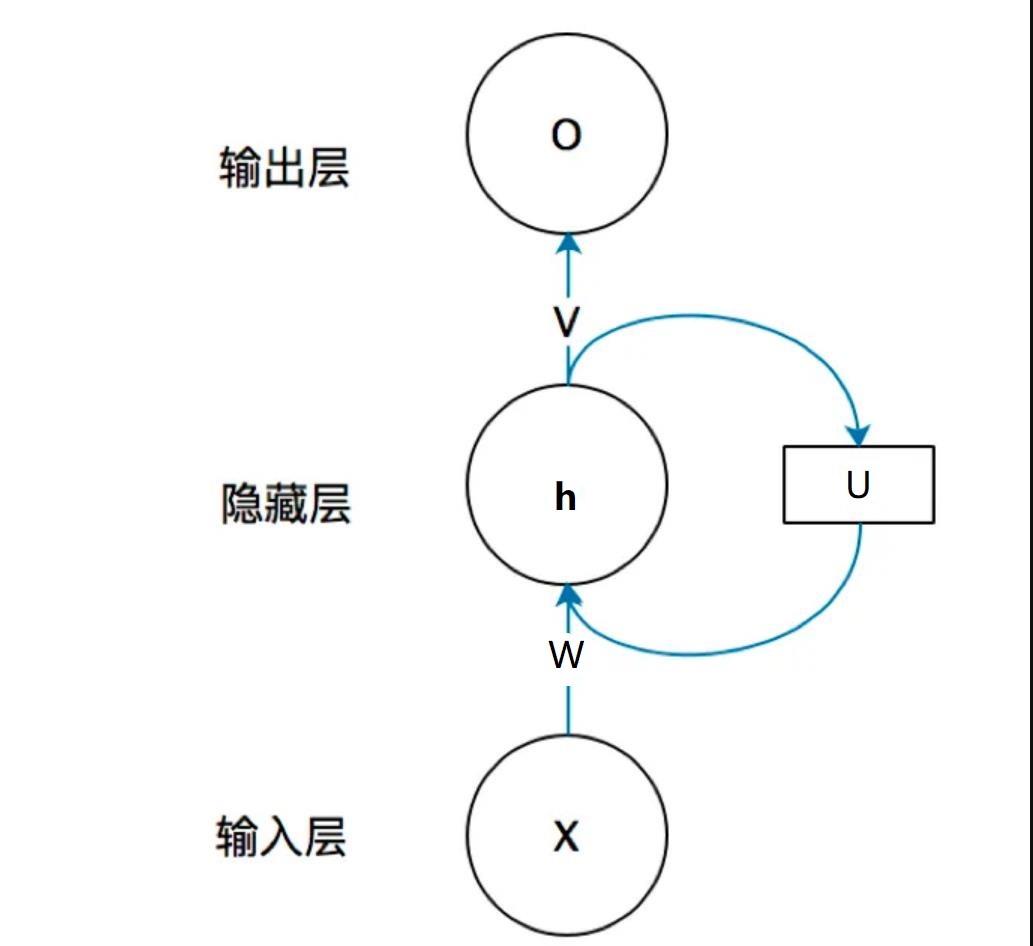
如图所示,这种结构与我之前所述的RNN意义一样,不过表达方式不同,当然,更新和之前的一样,使用BPTT算法。
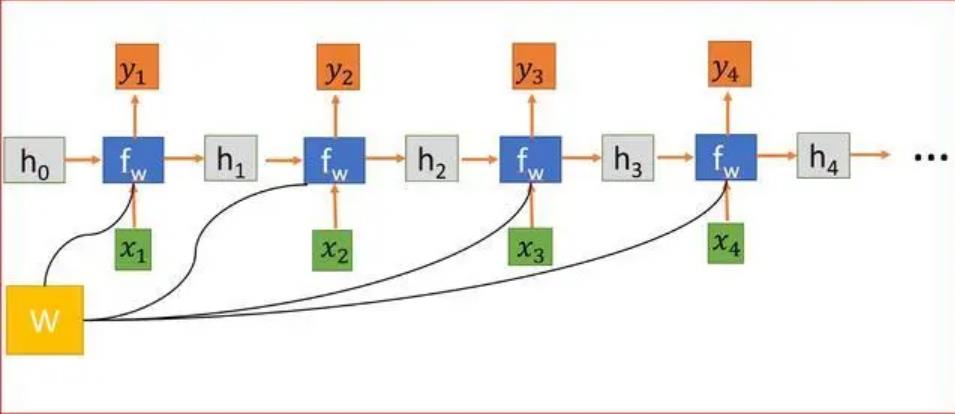
我给出之前博文的传送门:循环神经网络(RNN)的例子与他的训练算法
Seq2Seq
在上一篇RNN中,我们的序列结构都是输入与输出数目相同,这里还有一些其他形式,是我们接下来的重点。
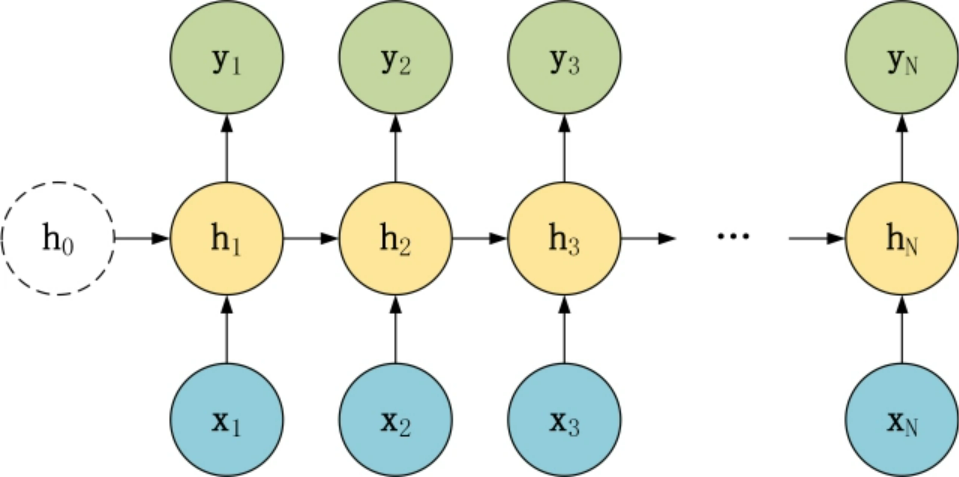
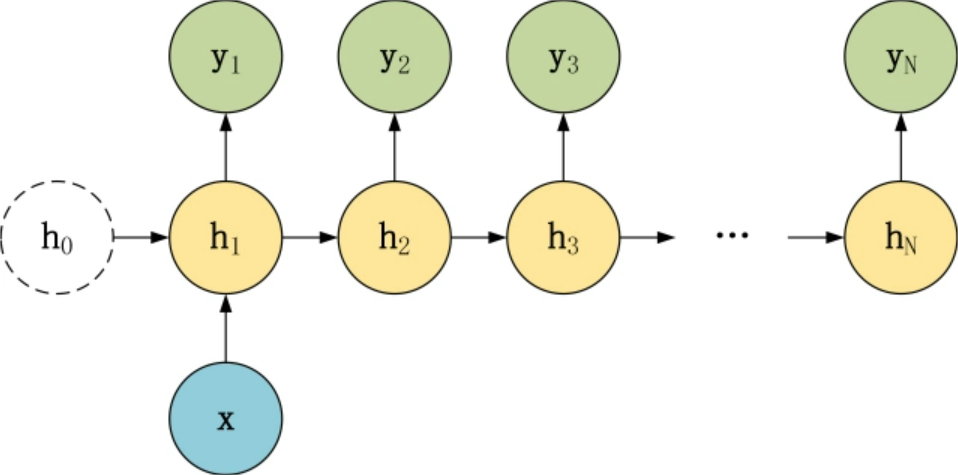
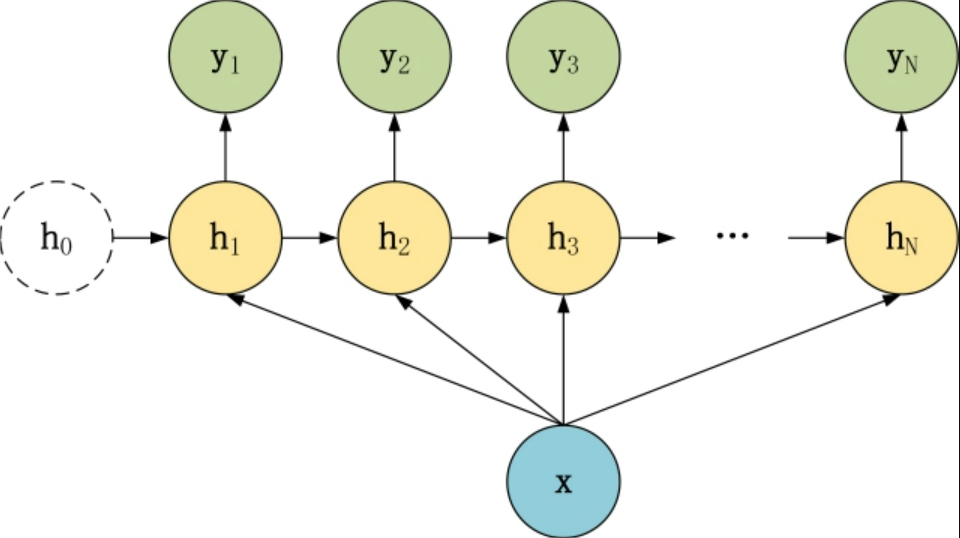
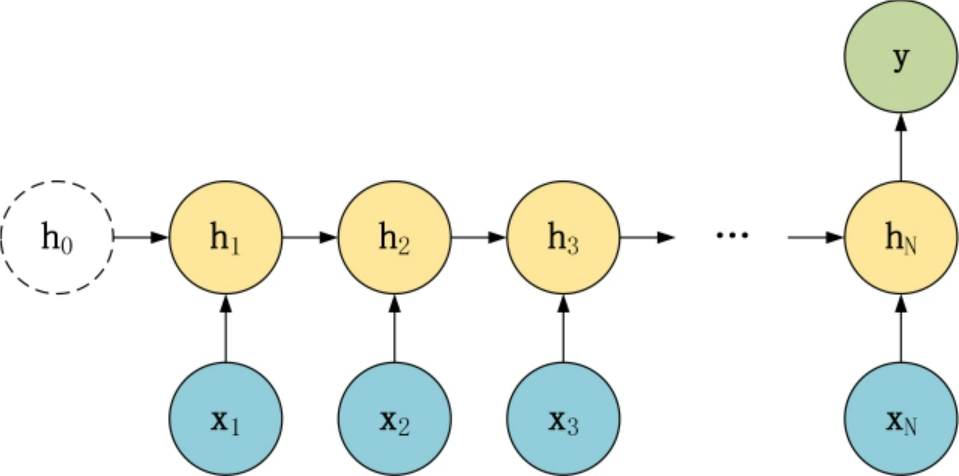
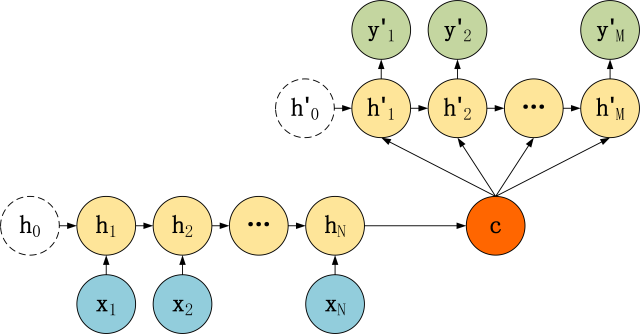
为什么列举这些呢?Seq2Seq的精髓就是编码(Encode)和解码(Decode),编码自然把N的数据进行归纳变成一个元素,也就是编码是N对1结构,而解码自然就是1对N的结构啦,同时为了让1对N结构能有良好的训练方式,也有一种将上一层的输出也作为本层的输入的形式(见7),这种形式也叫做Attention,这里展示一下Seq2Seq的结构。
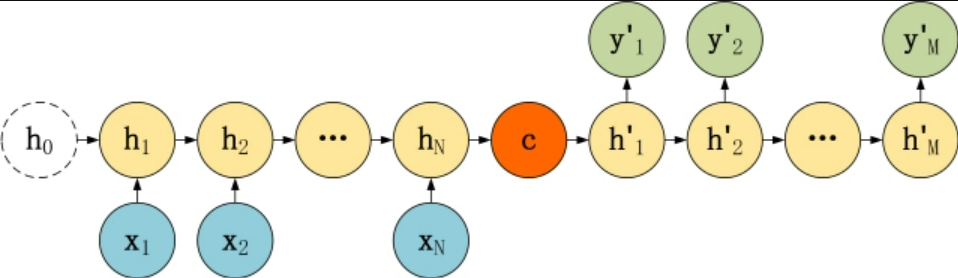
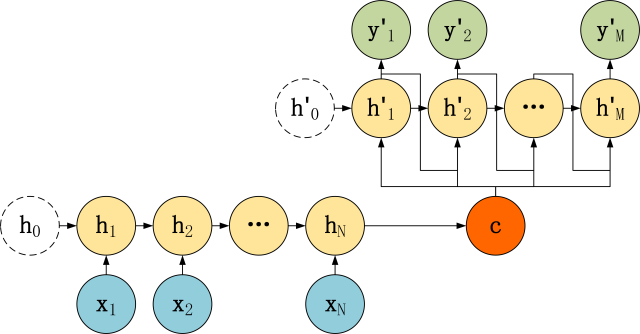
最简单的编码器,可以用以下方式计算:
解码器则大同小异,因为只有输入c的情况,所以就是RNN的每一个节点的输入都是c。我们再说一下它是如何训练的。
对于普通RNN的一个训练样本x1,x2,……,xT,其计算的概率是:当x1,x2,……,x(T-1)成立时时,xT成立的概率。即整个序列的概率为:
而我们的Seq2Seq输入输出都为序列,我们可以表示输入为x输出为y则让:
我们定义对数似然函数:
我们需要让输出最大,也就是对数似然的导数等于0。训练的过程就是在训练里面的LSTM,本质上相同,不过一般都不会用原味的Seq2Seq。
接下来我们加入Attention,图内的A只是表达一个LSTM计算的流程,可不是矩阵哦
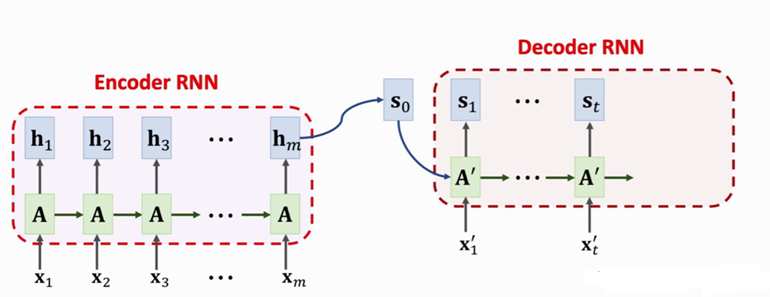
左侧编码器我们传递词典,也就是输入文本的word embedding,这时候我们需要给解码传递一个输出文本的word embedding,我们叫他$x’$。明确一下,大写字母均为矩阵,小写字母均为向量。
我们定义变量e,他表示s和h的运算结果,dot表示点积,它可以为:
其中h是编码网络所有h组成的向量,s同理。我们还需要根据不同输入提供注意力,所以我们依次进行计算,然后得到注意力的大小:
更新i的数值可以计算出所有的a得到向量,我们将最后的向量经过softmax计算,我们就得到了注意力向量(a)。这时候,我们让a 的第j项元素依次与h向量进行乘法,然后求和,即:
这样得到了一个新的向量,我们把他和前一个状态的s拼接在一起就可以迭代了s,也就是:
最后我们计算输出的概率,要注意,所有解码层的输出组合而成的向量才是最终的输出,这只是一个位置的输出:
上面的RNN表达的就是状态方程的计算,只是太长了,不愿意写了。
如何训练?
解码网络是负责最终输出的,所以我们可以先训练解码网络,注意,本质还是LSTM,解码器训练后就可以使用s去训练编码器。这里只是对已有的概念进行的扩展,计算方法没有变化。最后我们看一遍全部的过程。

Transformer
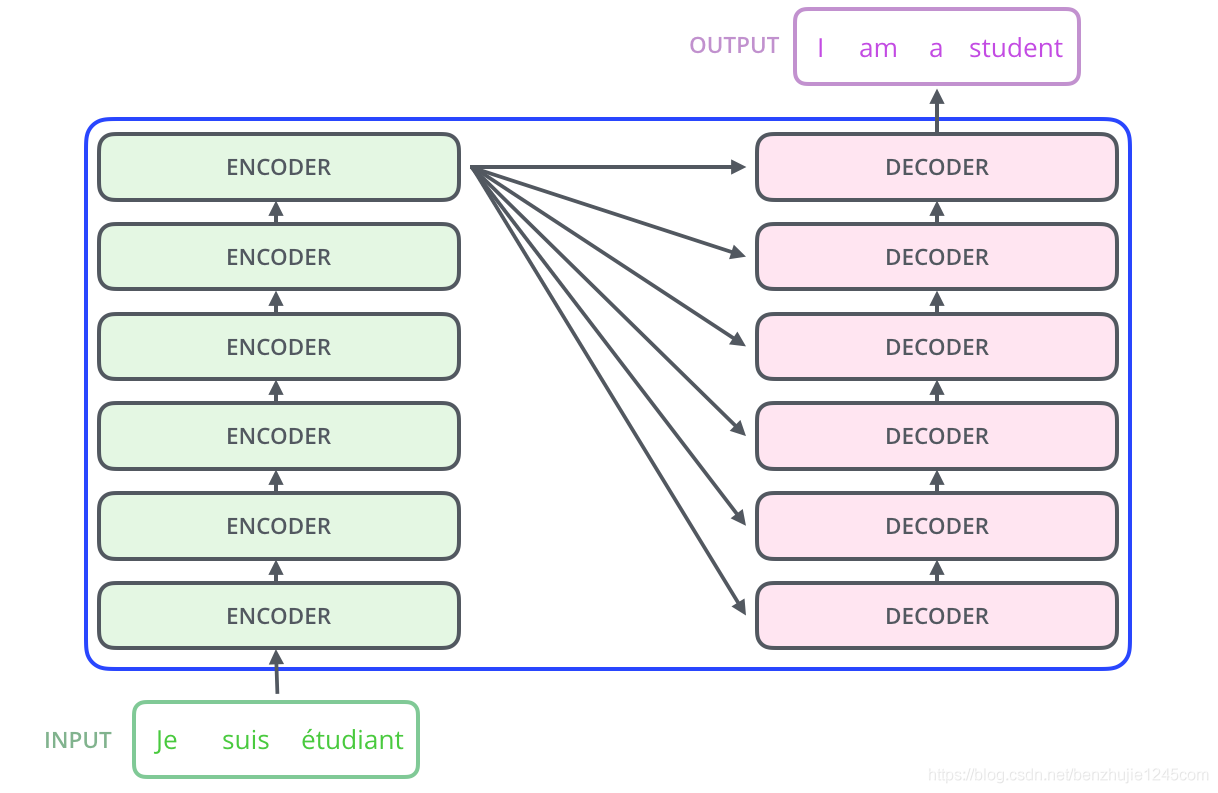
知道了Seq2Seq的单层编码解码结构后,我们接下来解释一下Transformer结构,这是多个编码器组合在一起,结构如下:
每一个EnCoder都是一样的结构,包含一个输入两个输出,一个Self attention层和一个前馈神经网络。从图上看,我们需要传递word embedding给Self attention,计算后的结果交给FNN,这样的数值最后会交给DeCoder单元。
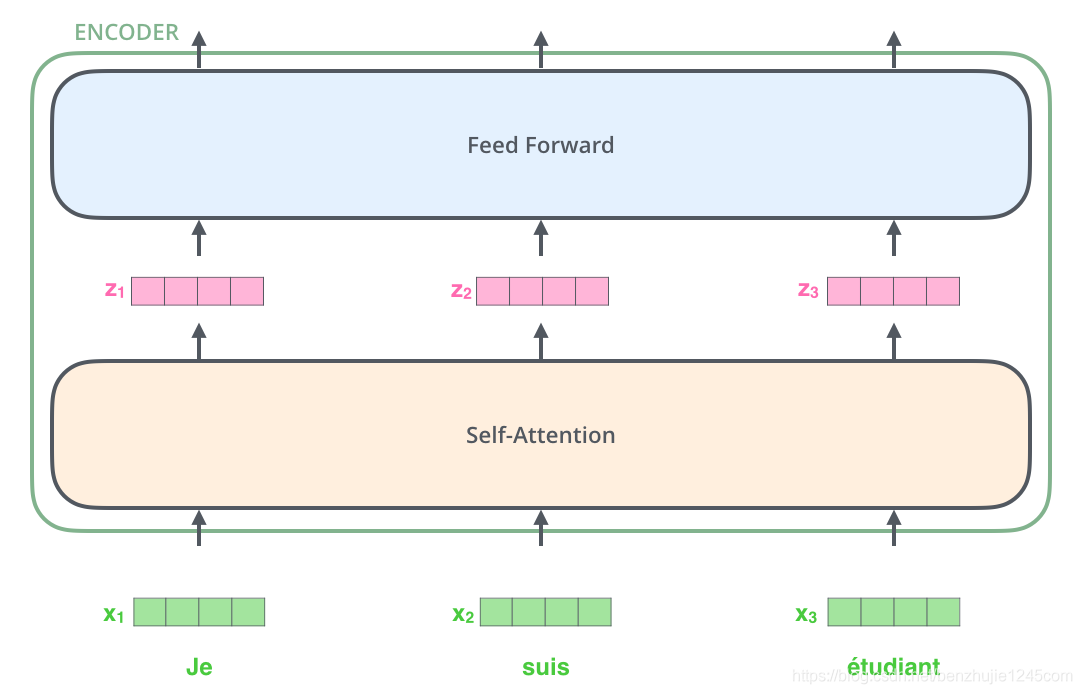
我们先看Self-Attention层的计算,这一层的过程与Seq2Seq有几分相似,我们看图说话:
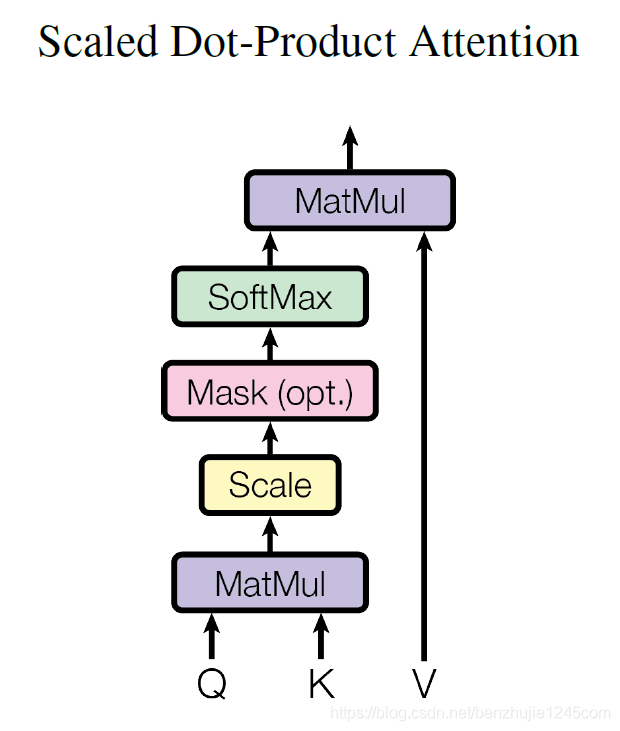
每一个输入的词向量我们定义为$x_i$,我们定义三个矩阵,分别负责将输入的词向量变成 q、k、v三个向量。我们将这样的三个矩阵命名为:$W_Q,W_K,W_V$。当然我们将所有q组成Q矩阵,k组成K矩阵….我们有计算公式:
$d_k=2^k$,它表示k向量的维度,当然这是从矩阵的秩定义的。
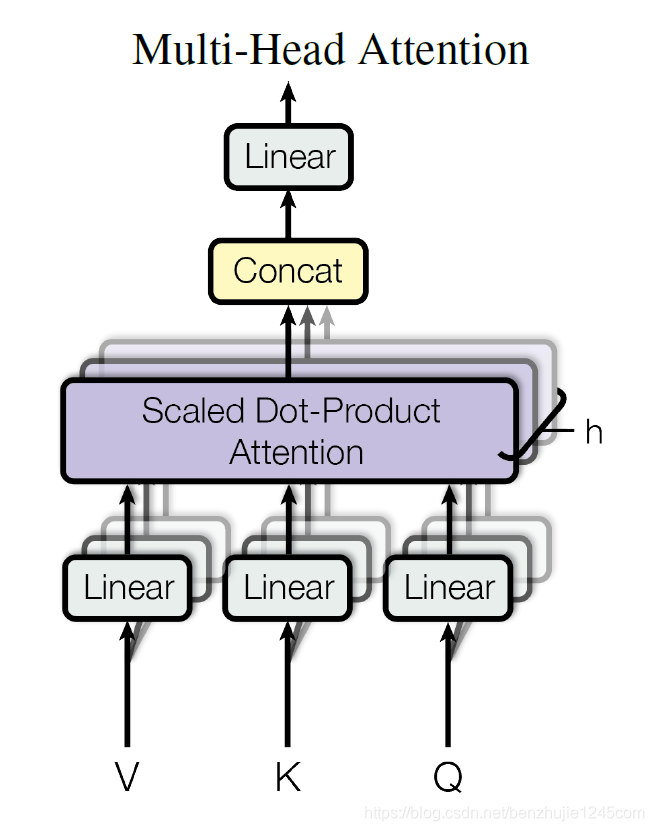
完善的Self-Attention被改名Multi-Head Attention(多头注意力)我们看图即可
多头注意力只是提供了8个的$W_K,W_Q,W_V$,将他们按照Self-Attention分别计算后得到8个Z矩阵,将他们拼接一起来后得到的向量使用一个更大的矩阵$W^O$缩小,可以根据需求选择形状。
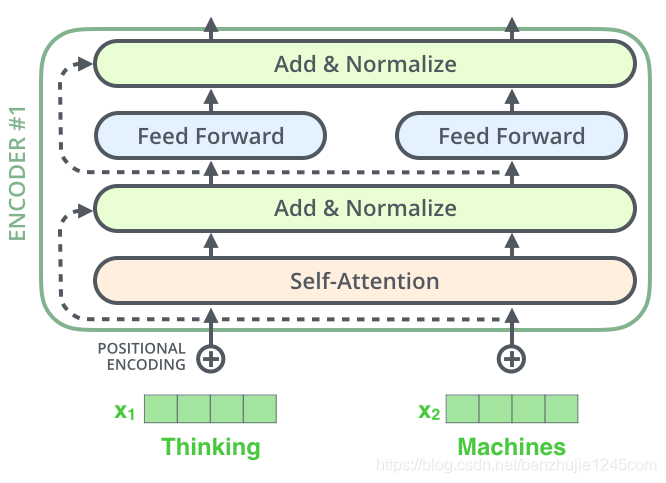
在每个编码器中的每个子层(自注意力、前馈网络)的周围都有一个残差连接,并且都跟随着一个Layer Normalization步骤。
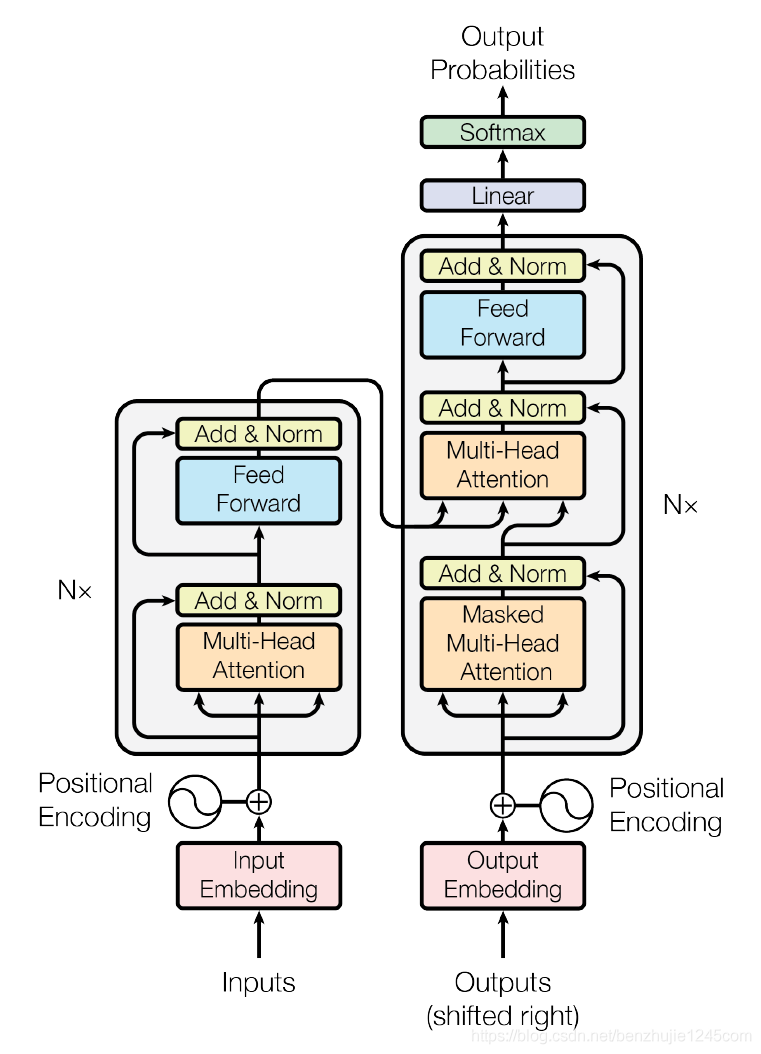
最后强调一点,这些结构训练依然遵循反向传播、BPTT,同时损失函数需要使用交叉熵。最后Transformers的输出重新给右侧做输入。右侧的开始输入可以是起始符,比如<SOS,结束为<EOS。
拓展
Mask Multi-head Attention
我们将注意力的矩阵适当元素位置变为0,这样就出现了Mask(掩码)。计算时把掩码矩阵乘以自注意力的向量即可。
总结
本期博文针对Seq2Seq的Attention进行了详细分析,以及Transformer模型进行了解读,之后Minloha将会同时更新NLP和CV的知识(闲得慌就多学点了)
文本参考
[1] 这么多年,终于有人讲清楚 Transformer 了
图片来源