关于22年电赛省赛实现传统视觉做倒车入库
分析
首先与机械组做好协调,使用TTL串口通信传递指令,我们使用了三位数,分别是控制前进、后退、停止,前轮的角度,云台的角度。这样我们就可以完全使用视觉控制系统完成倒车。
对于电控的部分,使用了STM32F3C8T6,舵机使用了5个2g舵机,主动轮使用了传统无刷电机,通过STM32修改PWM的占空比实现了舵机任意角度的旋转。不过电控我没看,我主要描述一下使用的视觉算法以及我期望的视觉算法。
首先我们分析一下特征,每个停车位都有一个箭头,所以我们需要识别它,至于倒车入库集体的实现交给STM32完成,所以我们视觉只需要通过串口告诉STM32:我看到了箭头即可。
传统视觉
为了提取特征,我们可以尝试进行卷积操作用来保留特征,然后通过对象识别来找到它。不过这里有一个很严重的问题,那就是嵌入式系统的算力并不高,对象识别并不准确,所以这个方案被舍弃了。
不过这种办法我也会在后面说,毕竟这种办法的精度很高
第二种就是我们使用的方法,就是特征点识别,首先我们要分析一个现实的情况:
在一个简单的光环境内,拍摄一个立体物体会有什么特点?

可以看到,在光下,自然的物体出现了阴影,也就意味着,阴影部分是一个光饱和度从低到高的过程。我用一张阴影图表示,斜线密度越大,阴影越深,光是从右上角照下来的,从图上看就是右上角的斜线密度大。
反映在灰度图片上我们可以发现,他的梯度是连续均匀的变化着的,所以我们可以得到结论,物体的边缘位置处,颜色值梯度是均匀变化的,而边缘位置近乎描述了物体的特征形状,所以通过此法可以获取到物体的特征。
如何实现这个过程呢?我们需要使用SIFT算法,SIFT主要分为以下两步:
- 创建高斯金字塔
- 确定梯度方向与关键点的梯度方向
首先拍摄一些目标的图片,然后我们采用从大图片逐步卷积为小图片的方法,完成上采样金字塔:

可以看到目标箭头的边角比较锐利,并未出现梯度值均匀变化的情况,而是直接的转变,这意味着这是一个与环境不相容的特征物体,所以我们取点要取在这种类型的物体边缘,这些点就是我们所需要的特征点。
构建过程简单来讲就是图片反复卷积,由大图变成小图,最后出来的就是特征。然后计算最后图片不同方向不同位置的梯度值,这样我们就得到了很多的特征点。
因为我们使用的是openMV,这些算法不需要我来完成,不过底层实现是SIFT算法。
1 | |
这个方法对于OpenMV来说,还是有些超负荷,所以接下来的CNN更加无法适用。
卷积神经网络
这种做法是我所希望的,因为只需要投入一定量的模型就可以识别的较为准确,因为特征较为明显,所以我只使用一层隐含层,并且只有两个输出,是或不是。下面是结构图:
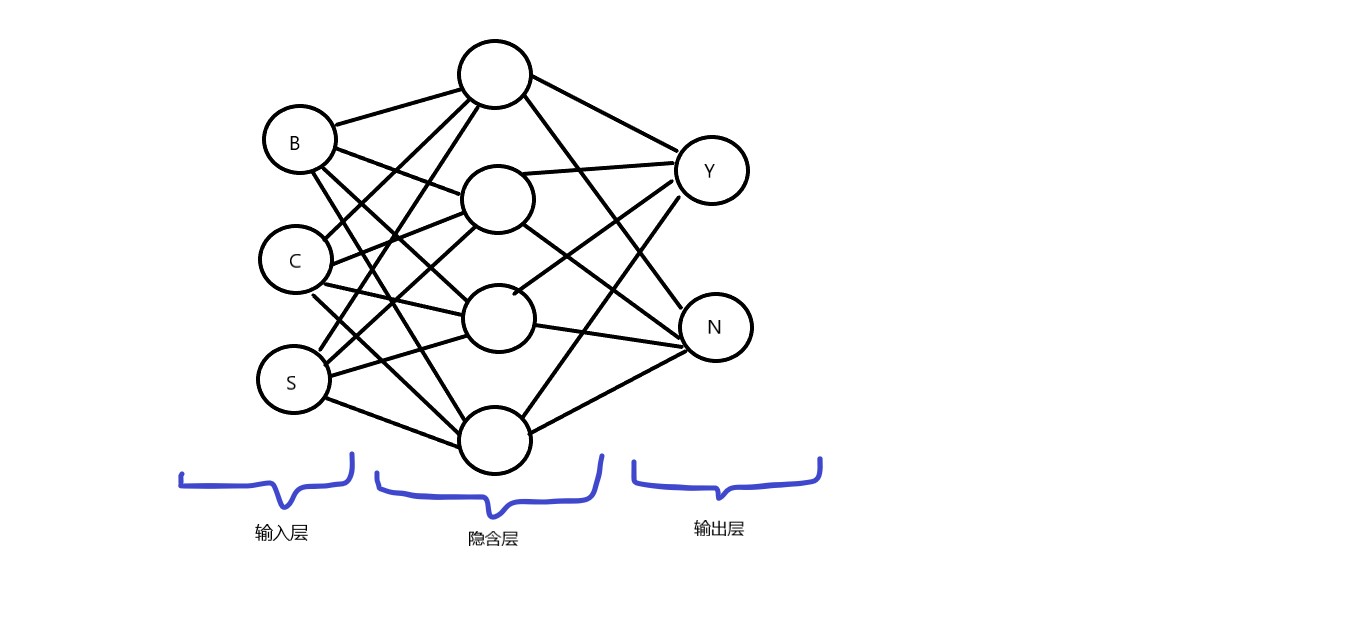
关于CNN的介绍我也就不再复习了,总体上可以参考我之前写过的文章,为了实现的简单与方便,我这里使用了Tensorflow完成操作,但是毕竟嵌入式的算力有限,没办法使用CUDA,如此只能简单的完成了。
玻尔兹曼机:https://blog.minloha.cn/2022/10/24/%E7%8E%BB%E8%80%B3%E5%85%B9%E6%9B%BC%E6%9C%BA/
1 | |
最后经过一夜的模型训练,精度几乎100%。
总结
这次比赛虽然最后还是输了,因为关键点忽然就全部消失了,而且在实际测试过程中openMV的线程卡死了,导致完全没办法跑完全程,只能说全都是经验吧!