1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
| import requests as rq
from bs4 import BeautifulSoup as bs
import pytesseract
from PIL import Image
import cv2
import numpy as np
usernames = "学号"
passwords = "密码"
def treat(img, threshold=127):
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, img = cv2.threshold(img, threshold, 255, cv2.THRESH_BINARY)
kernel = np.ones((2, 2), np.uint8)
img = cv2.erode(img, kernel, iterations=1)
img = cv2.dilate(img, kernel, iterations=1)
img = cv2.medianBlur(img, 3)
return img
def recognize_code(image):
image = image.convert('L')
table = []
threshold = 150
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
image = image.point(table, '1')
code = pytesseract.image_to_string(image, lang="eng")
result = ''.join(list(filter(str.isalnum, code)))
return result.strip()
def needCaptcha():
url = "https://authserver.hlju.edu.cn/authserver/needCaptcha.html?username=" + usernames
session = rq.Session()
re = session.get(url, allow_redirects=True)
re.cookies.clear()
if re.text.find("false") == 0:
return None
else:
img = session.get("https://authserver.hlju.edu.cn/authserver/captcha.html").content
with open("img.png", 'wb') as f:
f.write(img)
ig = treat(cv2.imread("img.png"))
cv2.imwrite("img.png", ig)
fileimg = Image.open('img.png')
return recognize_code(fileimg)
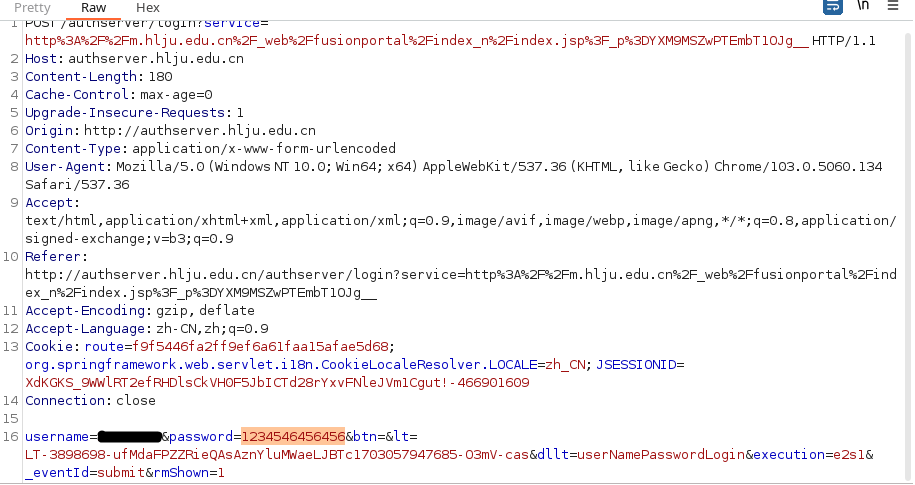
def buildPayLoad(username, password):
code = needCaptcha()
session = rq.Session()
url = "http://authserver.hlju.edu.cn/authserver/login"
html_page = session.request("get", url, allow_redirects=True).text
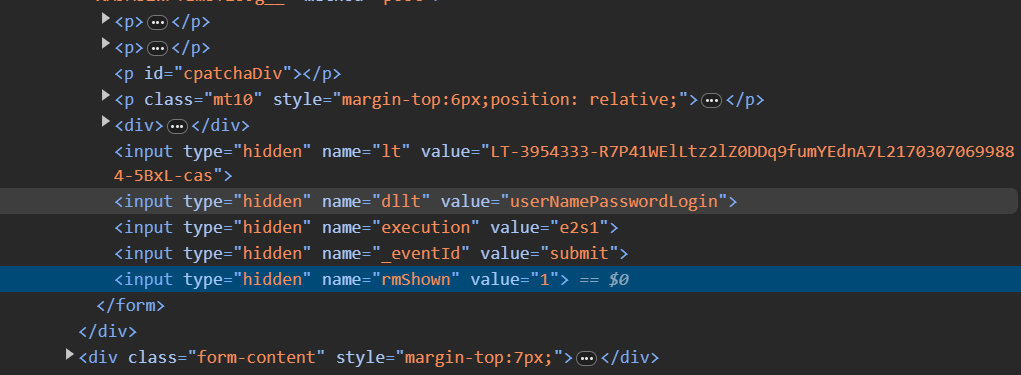
soup = bs(html_page, "html.parser")
safeURL = "http://authserver.hlju.edu.cn" + soup.find("form", {"id": "casLoginForm"})["action"]
lt = soup.find("input", {"name": "lt"})["value"]
execution = soup.find("input", {"name": "execution"})["value"]
eventID = soup.find("input", {"name": "_eventId"})["value"]
rmShown = soup.find("input", {"name": "rmShown"})["value"]
if code is not None:
return safeURL, {"username": username, "password": password, "captchaResponse" : code, "lt": lt, "execution": execution, "_eventId": eventID, "rmShown": rmShown}
else:
return safeURL, {"username": username, "password": password, "lt": lt, "execution": execution, "_eventId": eventID, "rmShown": rmShown}
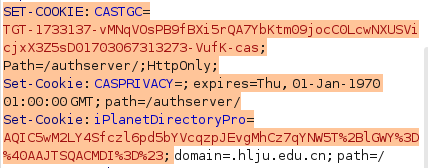
def buildCookie(cookie):
castgc = hlju_cookie.split(";")[0].split("=")[1]
route = hlju_cookie.split(";")[1].split("=")[1]
iPlanetDirectoryPro = hlju_cookie.split(";")[2].split("=")[1]
JSSESSIONID = hlju_cookie.split(";")[3].split("=")[1]
return {"CASTGC": castgc, "route": route, "iPlanetDirectoryPro": iPlanetDirectoryPro, "JSSESSIONID": JSSESSIONID}
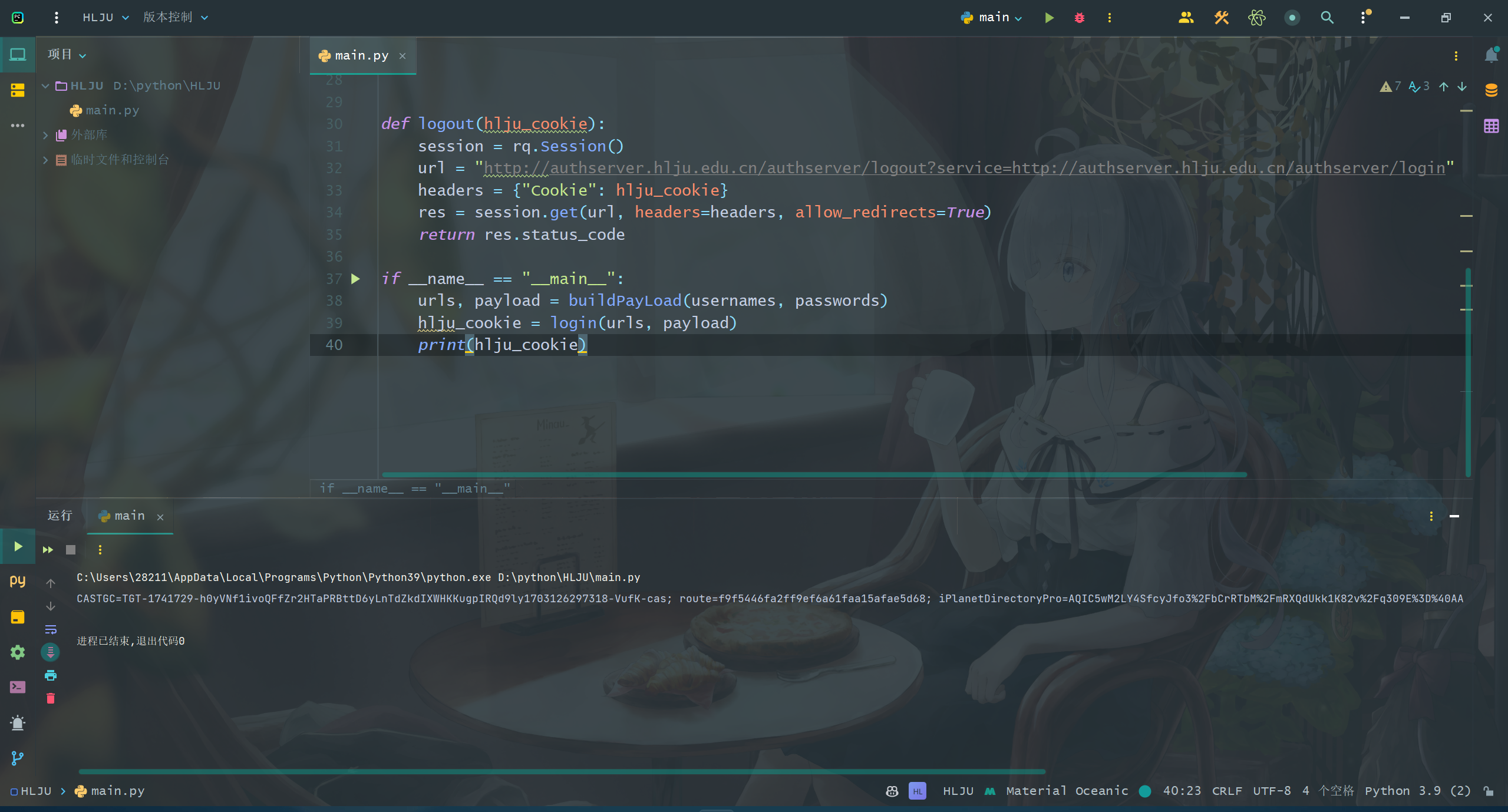
def login(urls, payload):
session = rq.Session()
res = session.post(urls, data=payload, allow_redirects=True)
while res.request.headers.get("Cookie").find("CASTGC") == -1:
session.cookies.clear()
res = session.post(urls, data=payload, allow_redirects=True)
return res.request.headers.get("Cookie")
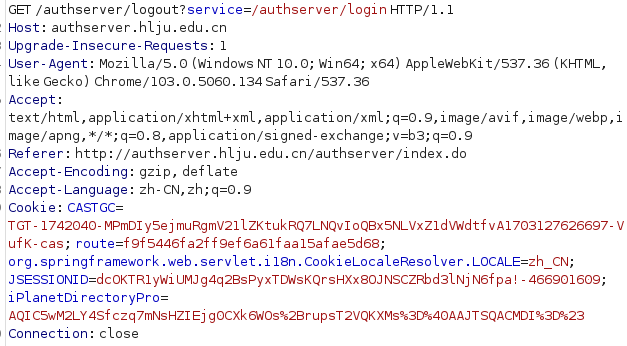
def logout(cookie):
ur = "http://authserver.hlju.edu.cn/authserver/logout?service=http://authserver.hlju.edu.cn/authserver/login"
session = rq.Session()
res = session.get(ur, allow_redirects=True, headers={"Cookie": cookie})
return res.request.headers.get("Cookie") is None
if __name__ == "__main__":
urls, payload = buildPayLoad(usernames, passwords)
hlju_cookie = login(urls, payload)
bd_cookie = buildCookie(hlju_cookie)
if logout(hlju_cookie):
print("登出成功")
|