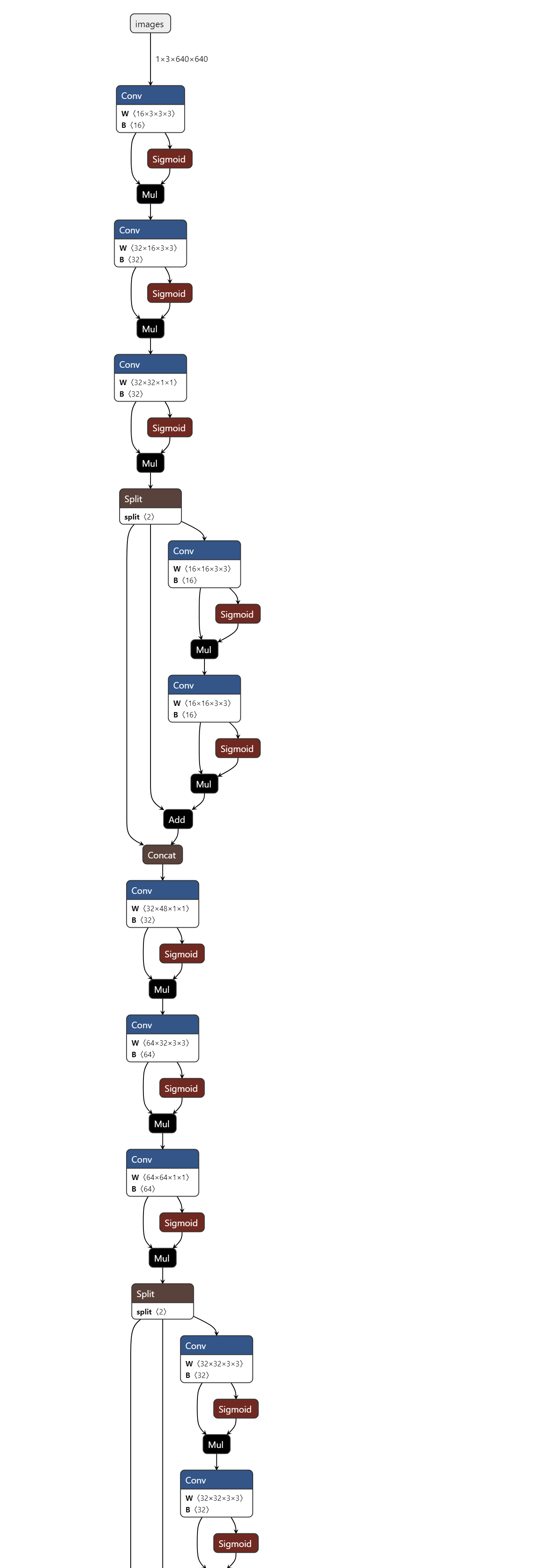
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
| #ifndef YOLOME_PREPROCESSING_HPP
#define YOLOME_PREPROCESSING_HPP
#include <iostream>
#include <vector>
#include <list>
using namespace std;
string names[] = {"person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light",
"fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow",
"elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee",
"'skis'", "'snowboard'", "'sports ball'", "'kite'", "'baseball bat'", "'baseball glove'", "'skateboard'", "'surfboard'",
"'tennis racket'", "'bottle'", "'wine glass'", "'cup'", "'fork'", "'knife'", "'spoon'", "'bowl'", "'banana'", "'apple'",
"'sandwich'", "'orange'", "'broccoli'", "'carrot'", "'hot dog'", "'pizza'", "'donut'", "'cake'", "'chair'", "'couch'",
"'potted plant'", "'bed'", "'dining table'", "'toilet'", "'tv'", "'laptop'", "'mouse'", "'remote'", "'keyboard'", "'cell phone'",
"'microwave'", "'oven'", "'toaster'", "'sink'", "'refrigerator'", "'book'", "'clock'", "'vase'", "'scissors'", "'teddy bear'",
"'hair drier'", "'toothbrush'"};
struct BOX
{
float x;
float y;
float width;
float height;
};
struct Object
{
BOX box;
int label;
float confidence;
};
bool cmp(Object &obj1, Object &obj2){
return obj1.confidence > obj2.confidence;
}
float iou_of(const Object &obj1, const Object &obj2)
{
float x1_lu = obj1.box.x;
float y1_lu = obj1.box.y;
float x1_rb = x1_lu + obj1.box.width;
float y1_rb = y1_lu + obj1.box.height;
float x2_lu = obj2.box.x;
float y2_lu = obj2.box.y;
float x2_rb = x2_lu + obj2.box.width;
float y2_rb = y2_lu + obj2.box.height;
float i_x1 = std::max(x1_lu, x2_lu);
float i_y1 = std::max(y1_lu, y2_lu);
float i_x2 = std::min(x1_rb, x2_rb);
float i_y2 = std::min(y1_rb, y2_rb);
float i_w = i_x2 - i_x1;
float i_h = i_y2 - i_y1;
float o_x1 = std::min(x1_lu, x2_lu);
float o_y1 = std::min(y1_lu, y2_lu);
float o_x2 = std::max(x1_rb, x2_rb);
float o_y2 = std::max(y1_rb, y2_rb);
float o_w = o_x2 - o_x1;
float o_h = o_y2 - o_y1;
return (i_w*i_h) / (o_w*o_h);
}
std::vector<int> hardNMS(std::vector<Object> &input, std::vector<Object> &output, float iou_threshold, unsigned int topk)
{
const unsigned int box_num = input.size();
std::vector<int> merged(box_num, 0);
std::vector<int> indices;
if (input.empty())
return indices;
std::vector<Object> res;
std::sort(input.begin(), input.end(),
[](const Object &a, const Object &b)
{ return a.confidence > b.confidence; });
unsigned int count = 0;
for (unsigned int i = 0; i < box_num; ++i)
{
if (merged[i])
continue;
Object buf;
buf = input[i];
merged[i] = 1;
for (unsigned int j = i + 1; j < box_num; ++j)
{
if (merged[j])
continue;
float iou = static_cast<float>(iou_of(input[j], input[i]));
if (iou > iou_threshold)
{
merged[j] = 1;
}
}
indices.push_back(i);
res.push_back(buf);
count += 1;
if (count >= topk)
break;
}
output.swap(res);
return indices;
}
float sigmoid(float x)
{
return 1.0 / (exp(-x) + 1.0);
}
#endif
|