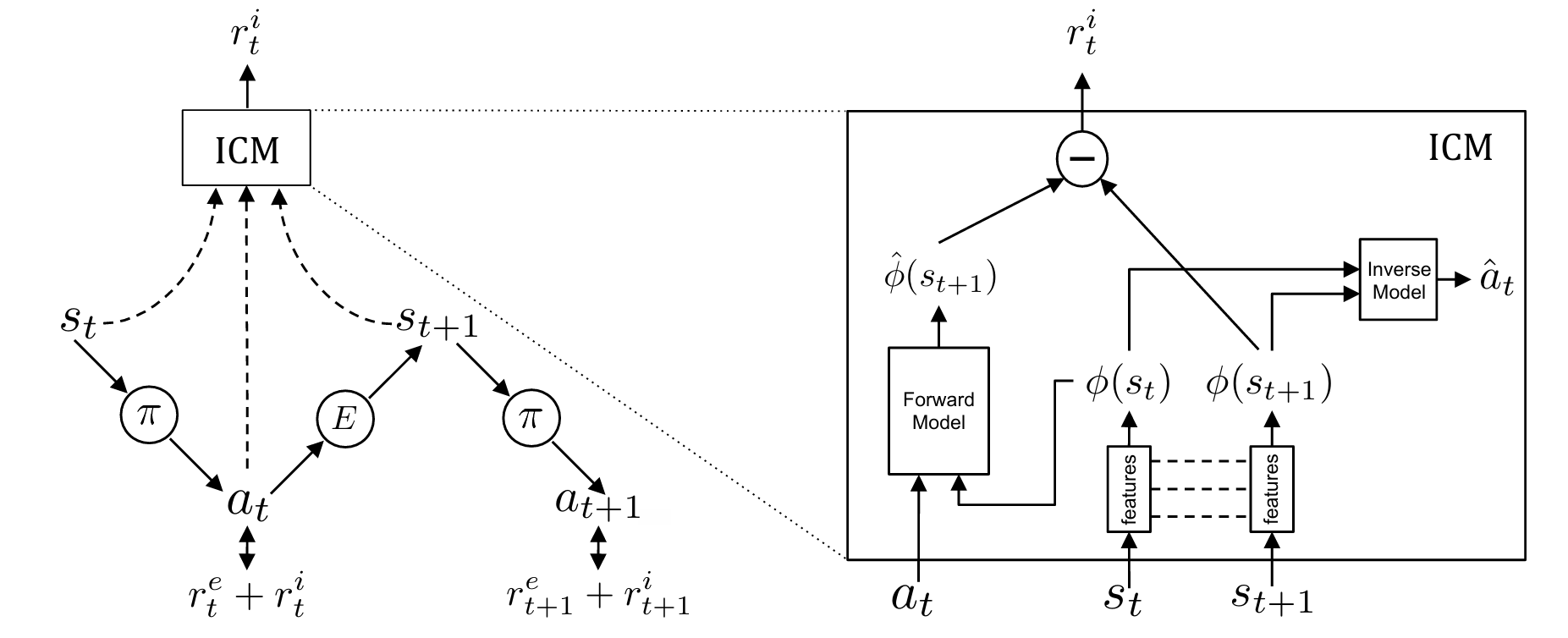
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
| import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
class Actor(nn.Module):
def __init__(self, state_dim, action_dim, max_action):
super().__init__()
self.l1 = nn.Linear(state_dim, 400)
self.l2 = nn.Linear(400, 300)
self.l3 = nn.Linear(300, action_dim)
self.max_action = max_action
def forward(self, state):
a = torch.relu(self.l1(state))
a = torch.relu(self.l2(a))
return self.max_action * torch.tanh(self.l3(a))
class Critic(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
self.q1_l1 = nn.Linear(state_dim + action_dim, 400)
self.q1_l2 = nn.Linear(400, 300)
self.q1_l3 = nn.Linear(300, 1)
self.q2_l1 = nn.Linear(state_dim + action_dim, 400)
self.q2_l2 = nn.Linear(400, 300)
self.q2_l3 = nn.Linear(300, 1)
def forward(self, state, action):
sa = torch.cat([state, action], dim=1)
q1 = torch.relu(self.q1_l1(sa))
q1 = torch.relu(self.q1_l2(q1))
q1 = self.q1_l3(q1)
q2 = torch.relu(self.q2_l1(sa))
q2 = torch.relu(self.q2_l2(q2))
q2 = self.q2_l3(q2)
return q1, q2
def Q1(self, state, action):
sa = torch.cat([state, action], dim=1)
q1 = torch.relu(self.q1_l1(sa))
q1 = torch.relu(self.q1_l2(q1))
return self.q1_l3(q1)
class TD3:
def __init__(
self,
state_dim,
action_dim,
max_action,
policy_noise=0.2,
noise_clip=0.5,
policy_freq=2,
tau=0.005,
gamma=0.99,
actor_lr=3e-4,
critic_lr=3e-4
):
self.actor = Actor(state_dim, action_dim, max_action).to(
torch.device("cuda" if torch.cuda.is_available() else "cpu"))
self.actor_target = Actor(state_dim, action_dim, max_action).to(
torch.device("cuda" if torch.cuda.is_available() else "cpu"))
self.actor_target.load_state_dict(self.actor.state_dict())
self.critic = Critic(state_dim, action_dim).to(torch.device("cuda" if torch.cuda.is_available() else "cpu"))
self.critic_target = Critic(state_dim, action_dim).to(
torch.device("cuda" if torch.cuda.is_available() else "cpu"))
self.critic_target.load_state_dict(self.critic.state_dict())
self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=actor_lr)
self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=critic_lr)
self.max_action = max_action
self.policy_noise = policy_noise
self.noise_clip = noise_clip
self.policy_freq = policy_freq
self.tau = tau
self.gamma = gamma
self.total_it = 0
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def select_action(self, state):
state = torch.FloatTensor(state.reshape(1, -1)).to(self.device)
return self.actor(state).cpu().data.numpy().flatten()
def train(self, replay_buffer, batch_size):
self.total_it += 1
state, action, reward, next_state, done = replay_buffer.sample(batch_size)
with torch.no_grad():
noise = (
torch.randn_like(action) * self.policy_noise
).clamp(-self.noise_clip, self.noise_clip)
next_action = (
self.actor_target(next_state) + noise
).clamp(-self.max_action, self.max_action)
target_Q1, target_Q2 = self.critic_target(next_state, next_action)
target_Q = torch.min(target_Q1, target_Q2)
target_Q = reward + (1.0 - done) * self.gamma * target_Q
current_Q1, current_Q2 = self.critic(state, action)
critic_loss = nn.MSELoss()(current_Q1, target_Q) + nn.MSELoss()(current_Q2, target_Q)
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
if self.total_it % self.policy_freq == 0:
actor_loss = -self.critic.Q1(state, self.actor(state)).mean()
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
for param, target_param in zip(self.actor.parameters(), self.actor_target.parameters()):
target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data)
for param, target_param in zip(self.critic.parameters(), self.critic_target.parameters()):
target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data)
|