[2]arm64 架构学习
中断与内存
在我们学习单片机的时候,一定会遇到中断问题,中断是外部信号造成PC寄存器数值改变,跳转到中断处理函数段的方法。这种方法可以有效避免单片机不正常运行而导致毁坏:中断包括指令中断和数据中断,通常是访问内存时发生了问题。
中断需要中断向量表用于映射PC值,在stm32中也叫做NVIC(中断向量控制器)对于所有ARM架构的芯片都有类似的结构。中断有两种,一种时是IRQ也就是普通中断,另一种就是FIQ是一种优先级更高的中断。中断在中断寄存器会保存当前PC值并根据中断控制器让它跳转到对应的指令段。这种寄存器保存在安全世界内,通过安全世界的物理定时器就可以把IRQ的中断源保存住。
我们看一下中断保存的内容,中断保存的内容保存在pt_regs结构体内,它包括:
1 | |
解释下结构体内容大概为:
- PSTATE寄存器
- PC值
- SP值
- 通用寄存器值
这样我们就保存住了当前程序状态的值进入内存之中。如果中断结束后想要恢复也可以通过ldr加载进入lr寄存器。
提及到中断还需要提及一下中断控制器,在STM32中叫做NVIC,通用一点的叫做GIC控制器,它可以通过处理外部信号进入中断中,GIC的中断可以处于如下四种状态:
- 不活跃:无效中断
- 等待:有效但等待CPU
- 活跃:已经进入中断
- 活跃并等待:进入中断但是等待CPU执行。
触发方式有两种:边沿触发(上升沿或者下降沿进入中断)电平触发(中断信号线产生高低电平)
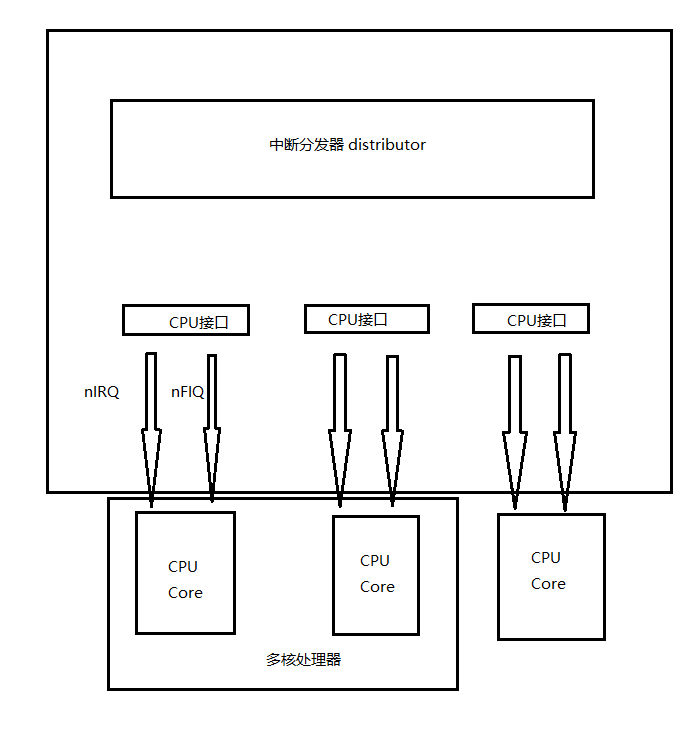
从图上可以看出作为大头的GIC拥有的中断分发器可以控制CPU接口,分发器主要就是仲裁和分发,CPU接口就是告知CPU执行对应内容。
这里使用stm32h7举例:
1 | |
从代码上可以看到stm32h7将内存分为几个区域,这就是ARM的内存管理策略,每几种相似设备分为一组只在某段内存空间上运行,比如我随机声明一个u8类型的内容他就会保存在RAM上,而Dx就是内存分组,从低到高分配。
1 | |
这里我声明了一个u16的数组RC_data,他的保存位置就在RAM_D1中,这段空间同时给了huart2使用,这段空间叫bss,对于跨界内存访问必须要使用对应的方法移动,而这种隔离内存的方法也叫做内存屏障。
缓存、DMA与内存屏障
缓存在CPU内,这是一个很好用的设备,CPU获取数据除了从主存读取外还可以搬到缓存内运行,这样每条指令的读取速度都会快很多。我们经常会产生疑问,为什么电流以接近光速运动还会出现速度快慢问题,答案很简单,空间越大结构越复杂的半导体,电流需要反反复复在半导体内运行,而半导体的载流子运动需要时间,这个时间不是光速。其次就是总线本身具有一定的阻抗,对于低频信号这点忽略不计,但是对于CPU着中国高速设备就不得不考虑复阻抗了,这个阻抗可能会造成信号异常,这样不得不迫使CPU重新读取数据。所以这就是严重限制速度的两点。那么都应该如何解决呢?
对于CPU而言,缓存是分等级的,等级越高空间越小结构越简单,速度越快。比如L1缓存,内存空间一般在几十KB,对于一般的数组存储是足够的。对于stm32h7的cortex-m7芯片而言这也是存在的,在CubeMx可以进行缓存启用。
缓存的工作机制很简单,对于主存储器而言,CPU通过对内存地址进行编码,通过地址总线和数据总线的配合实现数据的读写。缓存也是类似的道理。缓存访问使用的是虚拟地址,CPU会把虚拟地址同时传递给TLB和缓存,其中的TLB相当于一个把虚拟地址转化到物理地址的小缓存。
上文提到了,CPU可以从缓存中拿取指令,所以我们需要把外部存储的数据映射到缓存中,一共三种方法分别为:直接映射、全相连映射和组相连映射。第一种办法需要反复匹配数据,在这个过程中如果出现多组数据一起搬运的话就会出现内存颠簸(数据错误)。全相连映射把多组数据的内存地址映射到内存中,在这个过程中把所有关键的部分保留但没有对速度造成显著提高。
缓存的数据是从主存搬运的,为了确保数据不会出现动态修改,我们需要再增加一个功能就是缓存一致性。这里首先需要介绍一下MESI协议,如果你是多核CPU,当数据从内存取到缓存后,缓存中就包含了数据副本。如果CPU0运行后外部对数据进行了修改,那么其他的CPU无法保证实时获得数据。MESI协议可以确保外部数据修改后可以同时更新CPU缓存。
外部如何修改了数据?答案是DMA(直接内存访问),这是一种极其方便的东西,它可以在不经过CPU的情况下,直接把外部数据直接搬运到内存。这里我使用到了搬运这个词,DMA没有运算能力,仅仅相当于一条数据流水线。
缓存一致性通常是CPU内的处理器和内核的缓存一致性。系统间的缓存一致性包括CPU之间缓存一致性以及全系统间(不同设备比如CPU与GPU)的数据一致性。而为了确保这些要求,ARM提供了一个监听控制单元SCU。它可以全局广播缓存维护指令,可以实时监控数据变化。
内存屏障包含三种:
- 数据存储屏障(DMB):它可以确保所有存储器的访问都执行完毕后,才会执行后面的访问指令。DMB负责确保内存访问指令的顺序。
- 数据同步屏障(DSB):所有内存访问指令全部执行完只能,才会执行后面的指令。(任何指令)
- 指令同步屏障(ISB):确保所有在ISB指令之后的指令都能从指令缓存或者内存中重新领取。
DMB指令仅仅影响数据访问的序列。仅仅保证DMB前后内存访问指令的执行次序。