机器人学基础[控制章]——控制方法
介绍
本期内容主要是控制方法,但不要提到控制方法就想到PID,虽然本人也非常喜欢用PID。PID只是一种性价比较高的控制器,容易写并且消耗较低,应用范围也很广。但是复杂系统一般不会用PID控制。原因也很简单,PID就是比例+积分+微分,如果按传递函数讲,他就是一个二阶传递函数,也就意味着一个PID不可能控制超过二阶的系统。现实情况往往非常复杂,所以我们不得不学习很多的新方法。所以本期博客就是在基本的控制理论基础上进行延拓。当然有些较为先进的控制算法可以去查阅相关文献,有些算法固然经典,但是无法适应时代的进步。
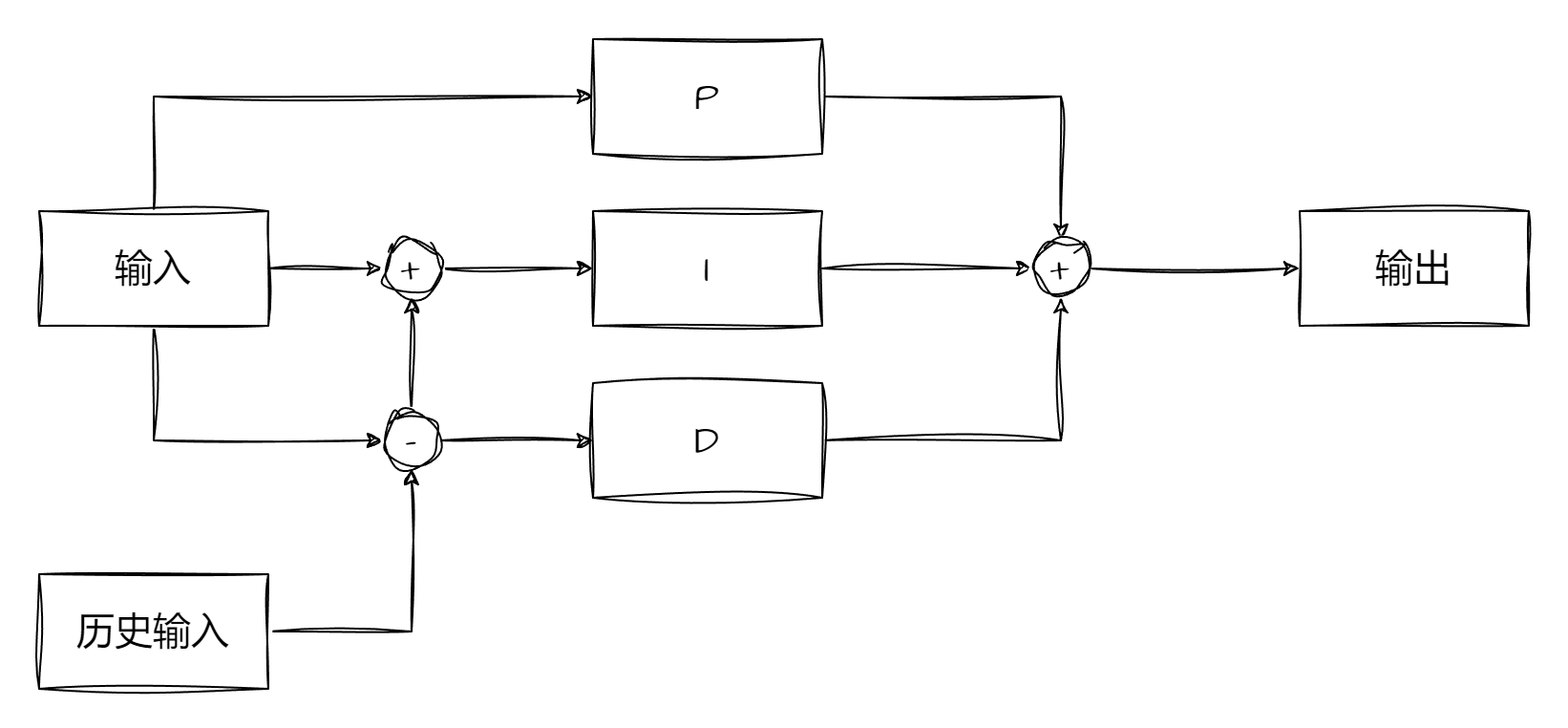
如图为基本的PID流程,这个过程几乎已经烂熟于心了,并且有不错的教材(自动控制原理)提及,所以本人就不过多赘述了。那么针对PID我们可以延伸出很多控制方法,诸如自适应PID、模糊PID、优化PID等。除了PID还有LQR这种基于惩罚函数的模型优化控制器,还有MPC这种纯粹的模型控制器等,所以我们无法单纯利用PID作为控制算法的中心,我们就需要抛开问题看本质,所以我们的控制器分类就按照控制方法进行了。
注意,划分的每一个章节都是一个单独的学科,章节名为学科名,内涵很多知识体系,因篇幅有限无法给出更多细节,所以如果不懂可以尝试搜索学习。
动力学建模
提到建模很多人都会有不同的联想对象,我这里说的是动力学建模,对于一个系统,他肯定可以用一定量的物理方程表示出来,无论是旋转的、摆动的、震荡的,这些都可以用数学表述。但是这些数学表述千奇百怪,我们必须要进行一定的约束,所以我们就需要进行专业的分析,首先我们需要给出状态方程的标准格式:
如上,这是最为基本的传递过程,其中x也叫状态向量,A叫做状态转移矩阵,B叫做输入控制矩阵,u为输入量,C为输出矩阵,y为输出量(并不参与控制)。对于一组数学表达式,我们总能转化为这种形式,我们可以用到线性代数的知识进行快速变化。当然也可以列些拉格朗日方程提取变量(这是个人感觉最快的,但是算量有点大)。我们以倒立摆举例:
倒立摆首先单摆可以写出力矩J,力矩可以用重物的质量m与摆长l的平方乘积表达:
定义L为拉格朗日量,其大小为系统的总动能减总势能,其中动能的大小可以通过力矩计算,根据基本的物理公式计算得到:
公式中的$\theta$为单摆的摆角,$\dot \theta$为摆角的一阶微分也就是角速度,再列写拉格朗日方程:
分别求出$\frac{\partial}{\partial t}\frac{\partial L}{\partial \dot \theta}$和$\frac{\partial L}{\partial \theta}$带入所有变量带入拉格朗日方程化简得到:
其中的g为重力加速度,是一个常量,而$\ddot \theta$为角度的二阶微分即角加速度。定义其状态变量可以得到:
将状态变量写作向量的形式就可以得到系统的状态向量表示为:
通过状态分量$x_2$可以发现这是一个非线性系统,为了书写其标准的状态空间方程,这里需要使其反馈线性化[13],先进行输出方程的列写即:
引入控制变量u,假设存在一个状态空间模型,包含状态更新矩阵A和控制输入矩阵B,则满足:
其中$\dot x$为状态向量的一阶微分,根据反馈线性化操作,可以通过同胚法或者李代数法[16]求出需要的反馈量。这里采用李代数法,求出C对x分量的导数$\frac{\partial C}{\partial x}$,得到:
其中的v为外界输入的激励信号,将所有变量代入得到:
通过这种方式,已经使得非线性项$\sin(\theta)$被反馈线性化处理掉,从而使得系统的动力学可以表示为一个线性系统,且控制输入v可以通过设计来控制系统的行为。对这个非线性系统可以把v设定为:
这里的$k$为反馈增益系数,为常数。引入后可以得到状态方程为:
而u又可以带入v的值,得到:
优化控制
提及优化,就很难不想到几种优化算法,大概可以分成有梯度和有约束函数两类,其中有梯度包括高斯牛顿法、狗腿法、动量法等等,约束函数又有惩罚函数,这些都是较为常用的优化方法,那么如何使用这些方法应用与控制领域就变成了如何转化这些方法。
动态规划
首先介绍DP(动态规划)方法,DP在算法题经常出现,其本质是一种牺牲空间换时间的方法,其算法可以间接的降低算法的时间复杂度,但是在控制领域,我们只需要考虑DP对数据的保存,顺便制定一种对结果的评估,我们写出系统的状态转移方程,姑且引入时间项:
同时还需要对系统进行结果评估,我们引入一个评判函数用于评判系统:
式子中出现了$\phi(x(t_{n}))$,它可以理解为一个惩罚项,而L函数可以看作在$t_0到t_n$这段时间内的误差累计。由实际可知我们无法连续分析,对此我们引入离散状态下的贝尔曼方程(就是强化学习基础的贝尔曼方程):
注意,这是一种在时间上的递推,并且是满足增量关系即:
其中的$\Delta t$ 是时间的微分,如果足够小就会使得这个方程变成微分方程,也就是著名的HJB方程:
而最优控制输出就是u,其值应使得梯度最小即目标值$u^*$应:
有了优化方法就可以将他融入到控制器,这里选择LQR方法:
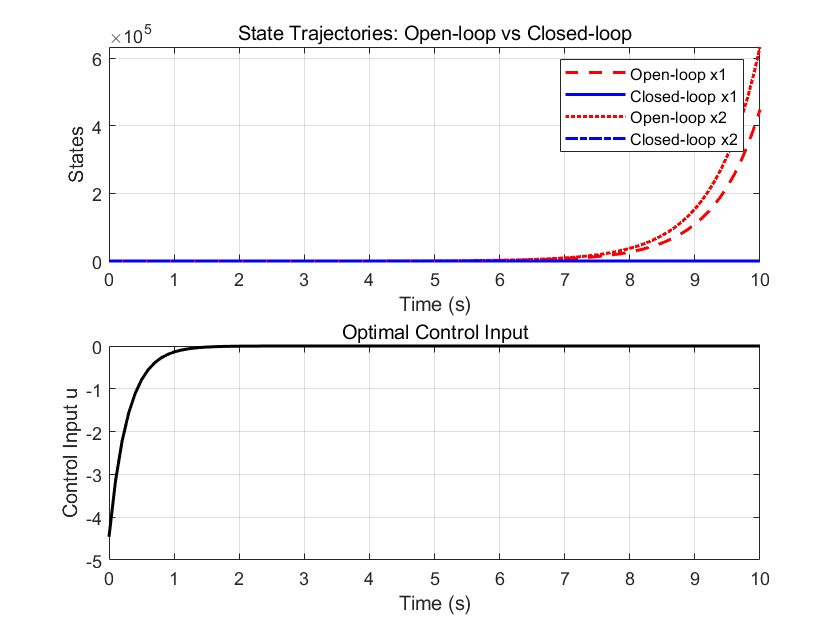
可以看到简单的倒立摆仿真效果非常好。
LQR方法
刚才提及到了LQR方法,这里我也说一下LQR方法,首先假设一个状态方程:
其中A叫做状态转移矩阵,B叫做输入控制矩阵,通过状态转移得到下一瞬间的状态向量$\dot x$,而控制LQR的最小化代价函数J为:
其中Q与R均为对角矩阵,Q用于惩罚系统误差而R用于控制系统输入,为了最小化代价函数让J值最小,为此引入辅助矩阵P,可以使:
假设系统是稳定的,这样最小化J可以写作:
结合可以计算得到:
这个方程也被叫做Algebraic Riccati Equation(ARE)[9],这些内容可以通过仿真模型的建立进行计算,最终就会得到确切的辅助矩阵P,然后就可以利用下面的公式计算反馈增益矩阵K了。
通过设定反馈矩阵就可以对系统进行控制了(基本的反馈控制思想,可以阅读现代控制理论一书),当然也可以尝试诸如反馈线性化、极点配置等老牌控制法。
Pontryagin最小值
庞特里亚金最大化原理
这也是一种最优化控制的重要方法,通过必要的变形可以变为Pontryagin最小值,与DP方法不同的是,它使用了变分法和哈密顿力学。
对此我们需要先下一个定义即,假设有一个最优控制u,那一定要满足:
- 状态方程与协态方程(共态方程)同时成立。
- 哈密顿函数在最优控制下取得全局最小值。
这里出现了优化控制理论的知识,补充一下:
哈密顿函数是连接状态方程和目标函数的关键桥梁。其定义为:
式子中的L是目标函数的瞬时成本(简单理解为目标函数),$\lambda$可以看作拉格朗日量,在方程内被称为协态变量。而f函数是状态的输入,一般写作u项
协态方程就是对哈密顿方程求x方向的偏导数得到$\lambda$与哈密顿方程的关系即:
归纳整理为数学语言就是:
1、状态方程
2、协态方程
3、最小值条件
接下来举个例子:
将小车从初始位置 $x(0) = x_0$ 移动到原点 $ x(t_f) = 0$,时间$t_f$最小化。
首先我们知道系统的位置x直接受到u的控制,所以可以写作:
利用评判函数,且优化到$t_f$可知,$J=t_f$:
简单换个元就得到:
所以L=1,我们得到哈密顿方程:
协态方程1可以写成:
所以$\lambda$全程保持不变,并且为了满足哈密顿函数的最小值,选择合适的u,从哈密顿方程分类讨论:
- $\lambda_0>0$,则$u^*=-1$
- $\lambda_0<0$,则$u^*=1$
将解带回到状态方程,分别得到两个解:
假设到达原点解出:到达原点时间为$t_f=x_0$满足事实。带入第二个情况得到:
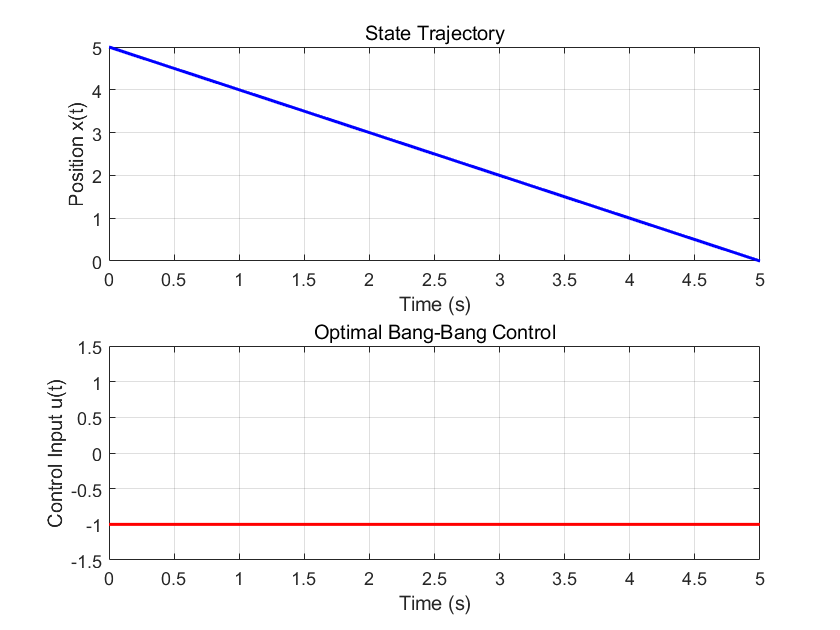
到达原点时间为$t_f=-x_0$,与目标矛盾,舍去。因这个例子中u仅有两组选择,我们引入Bang-Bang Control,也就是二值控制算法:
1 | |
绘制曲线得到位置和输入曲线,看起来很简单,就是保持一个值的递减,但是仅此而已罢了:
模型控制
模型控制或者说模型预测控制(MPC),它是一种基于滚动时域优化的控制策略,包含以下必要成分:
- 预测未来输出:利用系统模型预测未来一段时间内的状态或输出。
- 优化控制输入:在当前时刻求解一个有限时域的优化问题,得到最优控制序列。
- 实施首步控制:仅应用当前时刻的最优控制输入,下一时刻重新优化。
- 反馈校正:结合实际测量值修正预测模型,提升鲁棒性。
利用第一部分建模的知识我们很容易就能得到系统模型,当然这是一个连续的模型,我们可以前后差分得到离散模型即:
而其前后关系为:
其中$T_s$为采样周期。单纯的MPC非常的单纯,所以我们必须给出更为深奥的控制器。
动态矩阵控制
DMC即动态矩阵控制,核心就是动态矩阵,其构建本质为系统的阶跃响应系数。按照步骤可以如下划分
1.建立动态矩阵
首先对系统进行建模,然后传递阶跃信号,记录阶跃响应序列$a=\{a_1,a_2,a_3…a_n\}$(传递阶跃信号一段离散时间的数据),序列长度为N。
然后就可以构建动态矩阵A:
而这个矩阵是N行N列,但是系统可能在响应序列第M位就趋于稳定了,并且很容易知道M<N,所以我们需要对A进行截断,截断位置就是M处。同时还要迎合输入长度,即矩阵变为:
其中的p为输入量维度,用于预测时域长度,决定需预测的未来输出步数。M则控制时域长度,决定优化变量的维度。
2.预测模型
模型的P步预测又可以表述为下式:
- $\boldsymbol{Y}(k+1|k)$:未来$P$步的预测输出向量。
- $\boldsymbol{Y}_0(k+1|k$:基于过去控制输入的初始预测(无新控制增量时的自然响应)。
- $\Delta \boldsymbol{U}(k)$:未来 $M$ 步的控制增量向量 $[\Delta u(k), \Delta u(k+1), …, \Delta u(k+M-1)]^T$。
- 动态矩阵$A$的维度为$P \times M$。
3.优化目标函数
然后我们需要优化目标函数,DMC通过最小化跟踪误差和控制增量的加权和来求解最优控制:
- $\boldsymbol{Y}_{ref}$:参考轨迹(未来P步的期望输出)。
- Q与R:误差与控制增量的权重矩阵(通常为对角阵)
然后将预测模型代入目标函数,进行复杂的计算得到:
求解得到无约束的解析解,通过求导并令导数为零,得到最优控制增量:
- 关键矩阵:$A^T Q A + R$ 必须可逆(通常通过设计权重保证)。
- 实时性:若系统参数固定,可预先计算逆矩阵以减少在线计算量。
到此已经完成了基本的步骤,接下来进行递归操作:
4.首步控制
仅采用当前时刻的最优控制增量 $\Delta u(k)$,更新控制输入:
后续时刻重新执行预测和优化(滚动时域)。
5.反馈校正
由于模型误差和扰动,预测输出$\boldsymbol{Y}_0$可能与实际输出存在偏差。
校正方法*:
- 在时刻k,测量实际输出y(k)。
- 计算预测误差:$e(k) = y(k) - \hat{y}(k|k-1)$。
- 修正未来预测输出:
- $\boldsymbol{Y}_0^{\text{new}} = \boldsymbol{Y}_0^{\text{old}} + \boldsymbol{H} \cdot e(k)$
- 其中$ \boldsymbol{H}$为误差校正向量(通常取单位向量或滤波后的权重)。
最实用的部分便是如何设计参数,这里需要设定的参数很多,我写几个列表
对于时域P而言:
- 覆盖系统主要动态响应(P > M, M为截断处的长度)
- 如果过大就会对干扰敏感
- 过小就会导致控制激进
对截断长度M而言:
- 如果M很小则非常保守,变化很慢
- 如果M很大则响应速度加快,但是会增加计算量(A的维度)
Q与R:
- 增加Q就是让系统跟踪性能优先,可能引发控制量波动。
- 增加R就是控制增量抑制,系统响应变慢。
如果系统有约束则会变成二次规划问题,这里不多赘述,下面给出matlab仿真代码;
1 | |
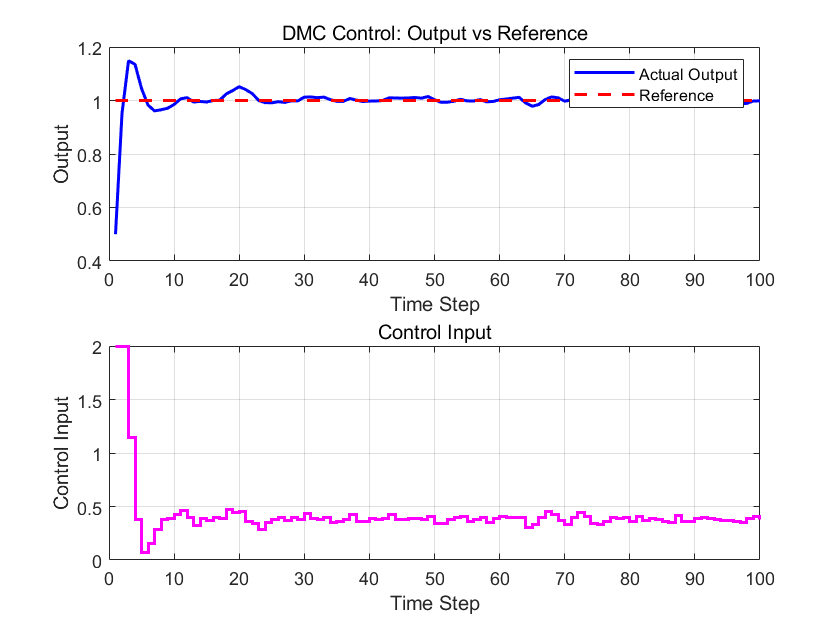
曲线可以看到我们的收敛时间非常非常快,虽然有点过冲,可以尝试调大P。但是总体效果非常好。
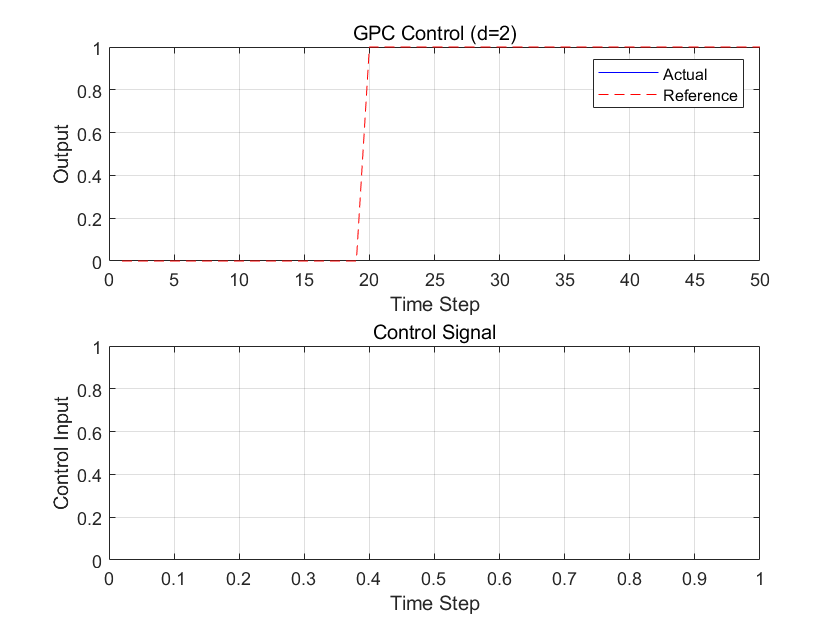
GPC
GPC也叫做广义预测控制,其本质基于数学模型CARIMA模型,通过多步优化进行控制,对比如下:
| 特性 | GPC | DMC |
|---|---|---|
| 模型类型 | 参数模型(CARIMA) | 非参数模型(阶跃响应/脉冲响应) |
| 噪声处理 | 显式建模随机扰动 | 依赖反馈校正 |
| 适用场景 | 随机扰动显著、模型复杂度高 | 确定性系统、低维动态 |
| 在线计算 | 需递归求解Diophantine方程 | 动态矩阵预计算 |
| 参数自适应性 | 支持在线参数估计(自校正GPC) | 固定模型参数 |
首先介绍一下CARIMA模型,其表达式的原始形式如下:
当然常见的会设$C=1$进而得到简单表达式,经过简单的运算得到下面的格式:
- $d$ 为系统延迟步数, $e(k)$为零均值白噪声。
- $\Delta = 1 - z^{-1}$:差分算子,用于消除稳态误差(积分作用)。
- $A(z^{-1}) = 1 + a_1 z^{-1} + \cdots + a_{n_a} z^{-n_a}$:输出的自回归多项式。
- $B(z^{-1}) = b_0 + b_1 z^{-1} + \cdots + b_{n_b} z^{-n_b}$:输入的滑动平均多项式。
- $d$:系统延迟步数(输入到输出的延迟)。
- $e(k)$:白噪声。
观察发现,这是一个针对离散系统的传递函数,其中的Z为特殊的拉普拉斯变换数值,即:$z=e^{j\omega}$,举个例子:
化成要求的格式得到:
为此左右两边同时乘以差分算子得到:
展开得到:
根据标准形式可以看出我们仅需处理$\Delta e(k)$,即:
所以得到:
列些其中的关键项即:
这里我重点强调一下,d本身并不为零,意味着系统天生存在2步滞后,这里很关键,在下文会用到
注意:差分算子是一种类似的积分算符,我尝试对整个方程进行了Z逆变换发现并不能得出求和或者积分项,原因也很简单,$\Delta$仅包含两个时刻的数据和,是一种等效的积分器,用表达式描述就是:
建立了CARIMA模型后我们需要进行长时间的预测,这里需要介绍一下Diophantine方程分解,这是一种对模型的处理,能够将模型分解为自由响应(过去输入输出的影响)和 受控响应(未来输入的影响),我们需要通过递归求解Diophantine方程得到多项式 $G_j, F_j$,方程的标准形式如下:
其中的j为步数,要求E和F的值,其值为多项式,如下:
而代求的$G_j$项又存在等式:
这样做的目的就是将未来输出$y(k+j)$ 分解为两部分:
- 自由响应(Free Response):由历史输入和当前状态决定的自然响应$ F_j y(k)$。
- 受控响应(Forced Response):由未来控制输入决定的响应$G_j \Delta u$。
我们继续按照之前的例子,假设j=1开始:
而j=1时,$E_1=e_0, F_1=f_0+f_1z^{-1}$,我们带入得到:
我们分别匹配$z^{0}、z^{-1}、z^{-2}$指数分别得到:
最终得到:
继续推理,当j=2时我们得到表达式:
展开表达式得到:
写作直观的表达式即:
继续匹配各项系数得到:
计算得到:
继续匹配得到:
综上所述得到:
有了这些过程我们就可以逐步得到G的数值,我们带入计算得到:
根据系数得到:$g_1 = 0.1$,因不包含z项,输出时无延迟的。
按照z的幂次得到系数为:$g_2^{(0)} = 0.1 , g_2^{(1)} = 0.19$
接下来需要构建预测方程,预测方程的表达式如下:
预测方程表示未来输出$\hat{y}(k+j)$的表达式,由自由响应和受控响应组成:
我们现在有j=1和j=2时刻的所有中间变量值,我们进行预测y的值:
我们需要继续分解j=3的Diophantine方程得到$F_3$,但为简化说明,假设利用j=1和j=2进而已计算得到:
接下来构建矩阵G,其表示未来控制增量对输出的影响其元素$ g_{i,j}$ 表示第$j$步控制增量对第$i$步输出的增益。
由于系统延迟$d=2$,控制增量 $\Delta u(k)$ 最早在第$ k+2$步影响输出。除了j=3以外都已经写出 $G_j(z^{-1})$ 的系数,这里省略步骤三的计算直接给出答案:
- $G_1(z^{-1}) = 0.1$
- $G_2(z^{-1}) = 0.1 + 0.19 z^{-1}$
- $G_3(z^{-1}) = 0.1 + 0.19 z^{-1} + 0.171 z^{-2}$
预测时域$N_p=3$,控制时域$N_u=2$,得到矩阵为(考虑到d=2):
其中:
- $g_{3,1} = 0.1$: $\Delta u(k)$ 对 $ y(k+3) $ 的增益(延迟2步后生效)。
- $ g_{4,1} = 0.19 $: $\Delta u(k)$ 的后续增益(动态特性)。
- $ g_{4,2} = 0.1 $: $\Delta u(k+1)$ 对 $ y(k+4) $ 的增益。
然后我们需要构建目标函数,目标函数权衡输出跟踪精度和控制量变化,一般写作下式:
将预测方程代入,化简为矩阵形式:
其中:
- $ \Delta \boldsymbol{U} = [\Delta u(k), \Delta u(k+1)]^T $: 待优化的控制增量。
- $ \boldsymbol{F} = [F_1(z^{-1}) y(k), F_2(z^{-1}) y(k), F_3(z^{-1}) y(k)]^T $: 自由响应向量。
- $ \boldsymbol{R} = [r(k+3), r(k+4), r(k+5)]^T $: 参考轨迹向量。
通过对 $ \Delta \boldsymbol{U} $ 求导并令导数为零,得到最优解:
最后我们就需要实时控制和优化了,过程非常简单,提取控制增量最优解的第一个元素:
然后就可以更新控制了:
自此循环下去。下面给出matlab代码:
1 | |