长短期记忆与门控 长短期记忆网络:: 接上期博客内容,在RNN的基础上添加LSTM和GRU,只需要把神经网络的模型修改一下即可,所以我们就可以新建一个LSTM类用于测试学习效果:
1 2 3 4 5 6 7 8 9 10 11 class LSTM (nn.Module):def __init__ (self, input_size, hidden_size, output_size ):super (LSTM, self ).__init__()self .net = nn.LSTM(input_size, hidden_size, num_layers=1 , batch_first=True )self .fc = nn.Linear(hidden_size, output_size)def forward (self, x ):self .net(x)self .fc(out[:, -1 , :])return out
然后实现一个LSTMtry方法用于测试LSTM的学习情况:
1 2 3 4 5 6 7 8 9 def LSTMtry (train_X, train_Y, test_X, test_Y ):1 , 3 , 1 )0.3 )
我们把上期博客的RNNtry换成LSTMtry,然后运行看看输出:
1 2 3 4 5 6 7 8 9 epoch 0, loss 0.0347
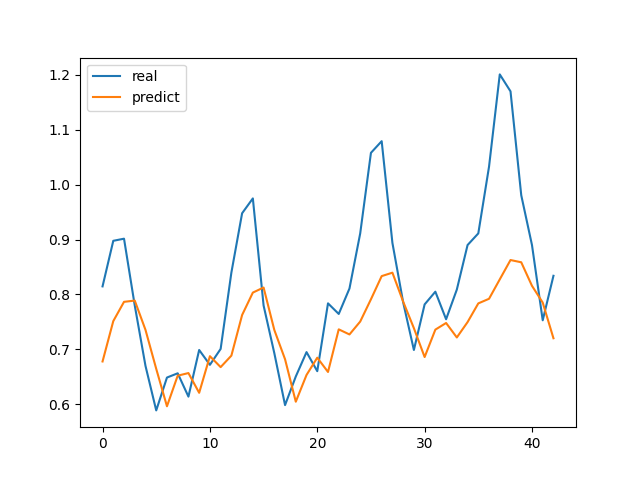
运行效果如图:
我们看到他比RNN的损失稍微高了一点点,但是因为我们的数据只有145个,如果数据量更大的话,效果会更好。
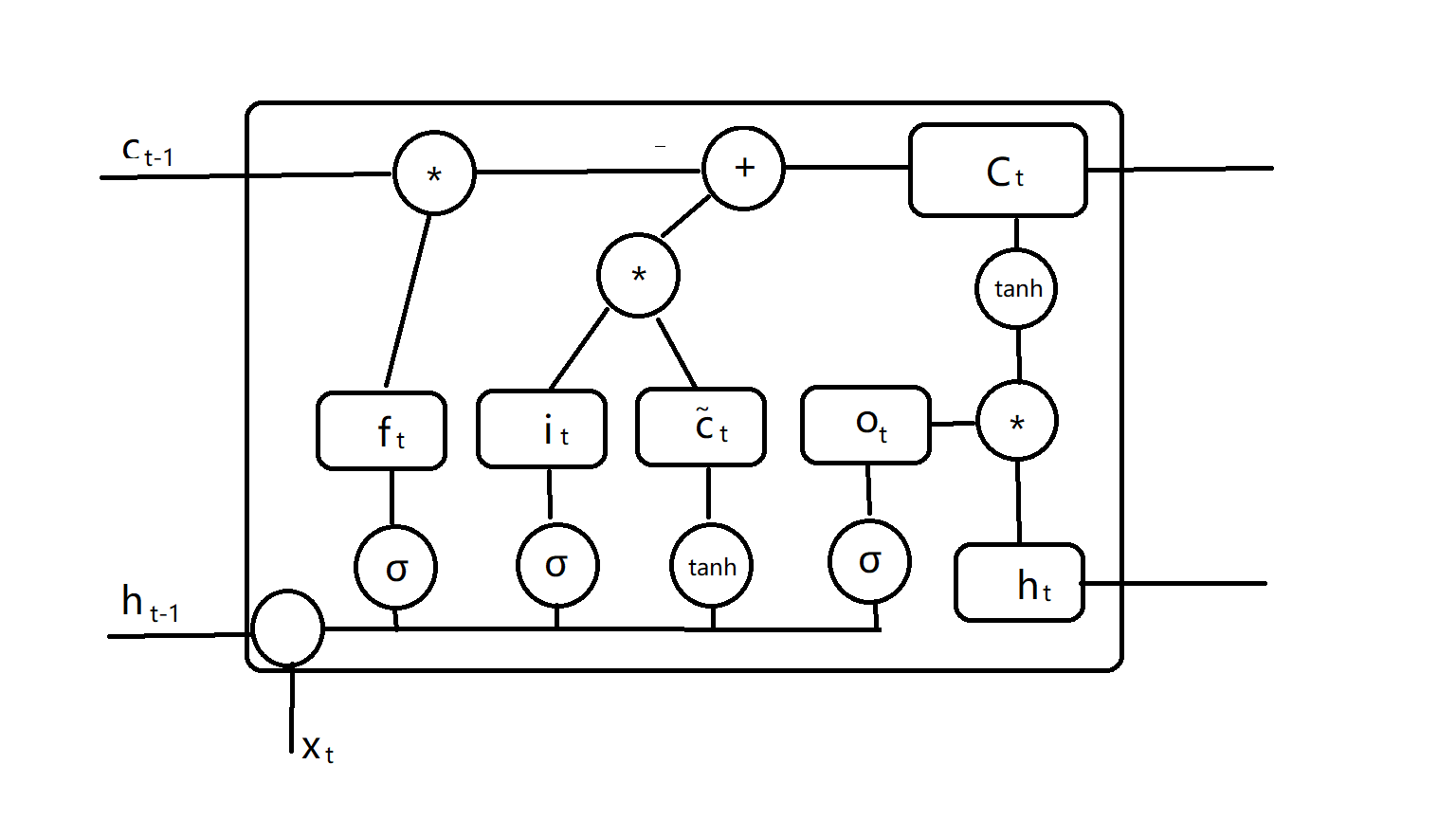
原理 为了保证能够拥有记忆时效,我们需要重新整理一下节点的结构,他需要一个输入(output),一个输出(input)和一个遗忘(forget),我们把这三部分都用门控表示,得到:
i为输入门,f为遗忘门,我们计算:
然后使用上一时刻的C计算当前时刻的C:
最后我们整合输出信息得到:
我们很容易就看出来,这种门控结构对输出内容进行了有效的限制,这样每个神经元结构就变成了这样(画了半天,真难受)
c是对状态的控制,实际上LSTM仍然可以使用BPTT进行训练。在处理输入时能够同时限制学习程度,非常好的解决了长程依赖的梯度爆炸和梯度消失问题。
门控循环网络:
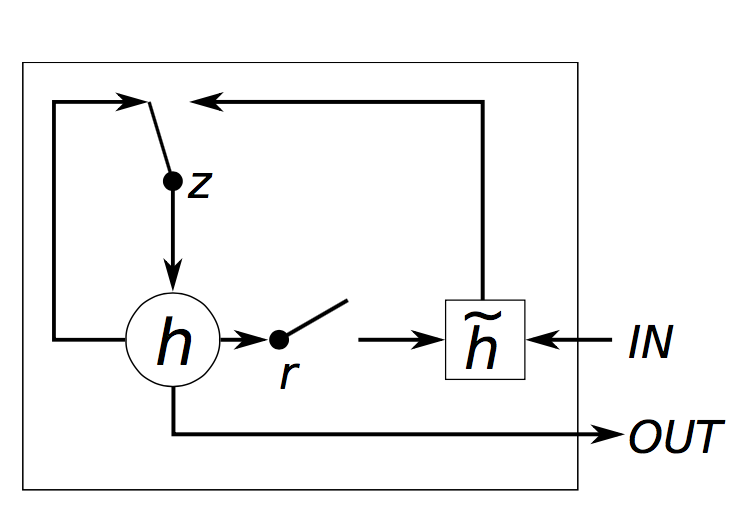
GRU(门控循环网络)的网络结果比LSTM稍微简单一点,将给一个单元都简化了一些,结构如图:
GRU使用了两个开关也就是重置门和更新门,使用两个单独参数控制,我们使用torch实现一个类完成GRU类:
1 2 3 4 5 6 7 8 9 10 class GRU (nn.Module):def __init__ (self, input_size, hidden_size, output_size ):super (GRU, self ).__init__()self .net = nn.GRU(input_size, hidden_size, num_layers=1 , batch_first=True )self .fc = nn.Linear(hidden_size, output_size)def forward (self, x ):self .net(x)self .fc(out[:, -1 , :])return out
GRU在torch.nn也实现过了,参数一样,我们再完成以下GRUtry方法。
1 2 3 4 5 6 def GRUtry (train_X, train_Y, test_X, test_Y ):1 , 3 , 1 )0.1 )
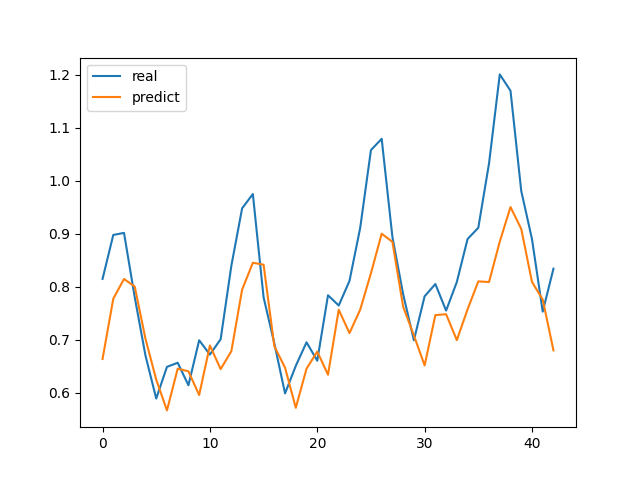
然后调用一下,当然一招鲜吃遍天。运行之后看看输出
1 2 3 4 5 6 7 8 9 epoch 0, loss 0.0336test loss 0.0137
我们对比一下,对于少量数据用RNN即可,介于两者之间的数据量用GRU即可,数量多最好用LSTM进行学习。
到目前为止我们就已经掌握了所有神经网络的结构,那么接下来我们介绍更高级的结构和功能
序列到序列 按顺序讲,序列到序列其实算自然语言处理部分了,当然这里也不难,直接开始说,接下来我们以中英文对照数据 演示,首先我们需要实现两个重要结构,对于Seq2Seq而言,我们需要将内容进行编码和解码,具体原理和流程可以看:https://blog.minloha.cn/posts/131918540f8d872023021922.html
我们需要实现Seq2Seq的编码器和解码器,我们只需要写如下内容即可,至于不将两者融合为一个Seq2Seq的原因是我们还需要对解码器进行修改。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class Encoder (nn.Module):def __init__ (self, input_size, hidden_size ):super (Encoder, self ).__init__()self .hidden_size = hidden_sizeself .embedding = nn.Embedding(input_size, hidden_size)self .gru = nn.GRU(hidden_size, hidden_size)def forward (self, input , hidden ):self .embedding(input ).view(1 , 1 , -1 )self .gru(output, hidden)return output, hiddendef initHidden (self ):return torch.zeros(1 , 1 , self .hidden_size, device=device)class Decoder (nn.Module):def __init__ (self, hidden_size, output_size ):super (Decoder, self ).__init__()self .hidden_size = hidden_sizeself .embedding = nn.Embedding(output_size, hidden_size)self .gru = nn.GRU(hidden_size, hidden_size)self .out = nn.Linear(hidden_size, output_size)self .softmax = nn.LogSoftmax(dim=1 )def forward (self, input , hidden ):self .embedding(input ).view(1 , 1 , -1 )self .gru(output, hidden)self .softmax(self .out(output[0 ]))return output, hiddendef initHidden (self ):return torch.zeros(1 , 1 , self .hidden_size, device=device)
这里我们发现比起LSTM,我们真正的使用到了hidden层的内容,因为GRU是手动控制循环值而LSTM是利用H层自动学习的,所以我们这里使用到了GRU门控,使用GRU就必须要初始化记忆层的输出变量。接下来是对训练数据的处理,这里我抄了Github的一段代码直接可以拿到训练数据的键值对,顺便对其进行频率向量估计:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 from io import open import unicodedataimport reimport numpy as np0 1 class ToLang :def __init__ (self, name ):self .name = nameself .word2index = {}self .word2count = {}self .index2word = {0 : "SOS" , 1 : "EOS" }self .n_words = 2 def addSentence (self, sentence ):for word in sentence.split(" " ):self .addWord(word)def addWord (self, word ):if word not in self .word2index:self .word2index[word] = self .n_wordsself .word2count[word] = 1 self .index2word[self .n_words] = wordself .n_words += 1 else :self .word2count[word] += 1 def unicodeToAscii (s ):return '' .join(for c in unicodedata.normalize('NFD' , s)if unicodedata.category(c) != 'Mn' def normalizeString (s ):r"([.!?])" , r" \1" , s)return sdef readLangs (lang1, lang2, reverse=False ):open (r"D:\python\RL\translate\data.txt" ,"utf-8" ).read().strip().split("\n" )for s in l.split("\t" )] for l in lines]2 , axis=1 )if reverse:list (reversed (p)) for p in pairs]else :return input_lang, output_lang, pairs"cmn" "fra" 10 "i am " , "i m " ,"he is" , "he s " ,"she is" , "she s " ,"you are" , "you re " ,"we are" , "we re " ,"they are" , "they re " def filterPair (p ):return len (p[0 ].split(' ' )) < MAX_LENGTH and \len (p[1 ].split(' ' )) < MAX_LENGTH and \1 ].startswith(eng_prefixes)def filterPairs (pairs ):return [pair for pair in pairs if filterPair(pair)]def prepareData (lang1, lang2, reverse=False ):print ("Read %s sentence pairs" % len (pairs))print ("Trimmed to %s sentence pairs" % len (pairs))for pair in pairs:0 ])1 ])return input_lang, output_lang, pairs'eng' , 'cmn' , True )
在得到数据后就是我们之前说过的,利用词频进行文本向量化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import dataTreat as dtdef indexesFromSentence (lang, sentence ):return [lang.word2index[word] for word in sentence.split(' ' )]def tensorFromSentence (lang, sentence ):return torch.tensor(indexes, dtype=torch.long, device=device).view(-1 , 1 )def tensorsFromPair (pair ):0 ])1 ])return input_tensor, target_tensor
接下来就是最后一步,完成数据的训练,这里我们的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 def train (input_tensor, target_tensor, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion, max_length=dt.MAX_LENGTH ):0 )0 )0 for ei in range (input_length):0 , 0 ]True if random.random() < teacher_forcing_ratio else False if use_teacher_forcing:for di in range (target_length):else :for di in range (target_length):1 )if decoder_input.item() == dt.EOS_token:break return loss.item() / target_length
然后我们写出trainIters进行反复多次的学习训练,这样我们就可以充分利用数据集:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 def asMinutes (s ):60 )60 return '%dm %ds' % (m, s)def timeSince (since, percent ):return '%s ' % asMinutes(s)''' :param encoder:编码器 :param decoder:解码器 :param n_iters:迭代次数 :param print_every:每隔多少次打印一次 :param plot_every:每隔多少次画一次图 :param learning_rate:学习率 ''' def trainIters (encoder, decoder, n_iters, print_every=100 , plot_every=100 , learning_rate=0.01 ):0 0 for i in range (n_iters)]for iter in range (1 , n_iters + 1 ):iter - 1 ]0 ]1 ]if iter % print_every == 0 :0 print ('Time: %s Iterator: %d%% Acc: %.4f' % (timeSince(start, iter / n_iters), iter / n_iters * 100 ,if iter % plot_every == 0 :0
然后我们在写一个前向传播的算法,用于将我们的中文翻译为英文:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 def evaluate (encoder, decoder, sentence, max_length=dt.MAX_LENGTH ):with torch.no_grad():0 ]for ei in range (input_length):0 , 0 ]for di in range (max_length):1 )if topi.item() == dt.EOS_token:'<EOS>' )break else :return decoded_words, decoder_attentions[:di + 1 ]
最后我们实现一下显示函数和main函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def showPlot (points ):0.2 )10 , 5 , 10 ]if __name__ == "__main__" :256 20000 , print_every=500 )"我是天才" )print (back)
这样经过我们就需要40次循环我们就训练完Seq2Seq了,次数越多我们的精度越高,但是时间也越多,基本在3分钟左右。我们看一下输出内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 Read 29668 sentence pairs'she' , 'is' , 'a' , 'inches' , '.' , '.' , '.' , '.' , '.' , '.' ]
我们发现虽然输出内容有点感觉但是精度还是不够,除了增加训练次数,又该如何优化呢?答案是增加注意力机制,具体内容可以去看https://blog.minloha.cn/posts/131918540f8d872023021922.html
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class AttnDecoder (nn.Module):def __init__ (self, hidden_size, output_size, dropout_p=0.1 , max_length=MAX_LENGTH ):super (AttnDecoder, self ).__init__()self .hidden_size = hidden_sizeself .output_size = output_sizeself .dropout_p = dropout_pself .max_length = max_lengthself .embedding = nn.Embedding(self .output_size, self .hidden_size)self .attn = nn.Linear(self .hidden_size * 2 ,self .max_length) self .attn = nn.Linear(self .hidden_size * 2 , self .max_length)self .attn_combine = nn.Linear(self .hidden_size * 2 , self .hidden_size)self .dropout = nn.Dropout(self .dropout_p)self .gru = nn.GRU(self .hidden_size, self .hidden_size)self .out = nn.Linear(self .hidden_size, self .output_size)def forward (self, input , hidden, encoder_outputs ):self .embedding(input ).view(1 , 1 , -1 )self .dropout(embedded)self .attn(torch.cat((embedded[0 ], hidden[0 ]), 1 )), dim=1 )0 ),0 )) 0 ], attn_applied[0 ]), 1 ) self .attn_combine(output).unsqueeze(0 )self .gru(output, hidden)self .out(output[0 ]), dim=1 )return output, hidden, attn_weightsdef initHidden (self ):return torch.zeros(1 , 1 , self .hidden_size, device=device)
我们这个时候就需要修改一下训练方法了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 def train (input_tensor, target_tensor, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion, max_length=dt.MAX_LENGTH ):0 )0 )0 for ei in range (input_length):0 , 0 ]True if random.random() < teacher_forcing_ratio else False if use_teacher_forcing:for di in range (target_length):else :for di in range (target_length):1 )if decoder_input.item() == dt.EOS_token:break return loss.item() / target_lengthdef trainIters (encoder, decoder, n_iters, print_every=100 , plot_every=100 , learning_rate=0.01 ):0 0 for i in range (n_iters)]for iter in range (1 , n_iters + 1 ):iter - 1 ]0 ]1 ]if iter % print_every == 0 :0 print ('Time: %s Iterator: %d%% Acc: %.4f' % (timeSince(start, iter / n_iters), iter / n_iters * 100 ,if iter % plot_every == 0 :0
然后我们修改一下评估函数,让它能够显示注意力热图:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 def evaluate (encoder, decoder, sentence, max_length=dt.MAX_LENGTH ):with torch.no_grad():0 ]for ei in range (input_length):0 , 0 ]for di in range (max_length):1 )if topi.item() == dt.EOS_token:'<EOS>' )break else :return decoded_words, decoder_attentions[:di + 1 ]def evaluateRandomly (encoder, decoder, n=10 ):for i in range (n):print ('>' , pair[0 ])print ('=' , pair[1 ])0 ])' ' .join(output_words)print ('<' , output_sentence)print ('' )def showAttention (input_sentence, output_words, attentions ):111 )'bone' )range (len (input_sentence.split(' ' ))), input_sentence.split(' ' ))1 ))1 ))def evaluateAndShowAttention (input_sentence ):print ('input =' , input_sentence)print ('output =' , ' ' .join(output_words))
最后我们修改一下main函数即可:
1 2 3 4 5 6 7 if __name__ == "__main__" :256 20000 , print_every=500 )"我最帅!" )
大约等待2分钟我们就可以看到输出内容了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 Read 29668 sentence pairs'i' , 'am' , 'cool' , '' , '.' , '.' , '.' , '.' , '.' , '.' ]
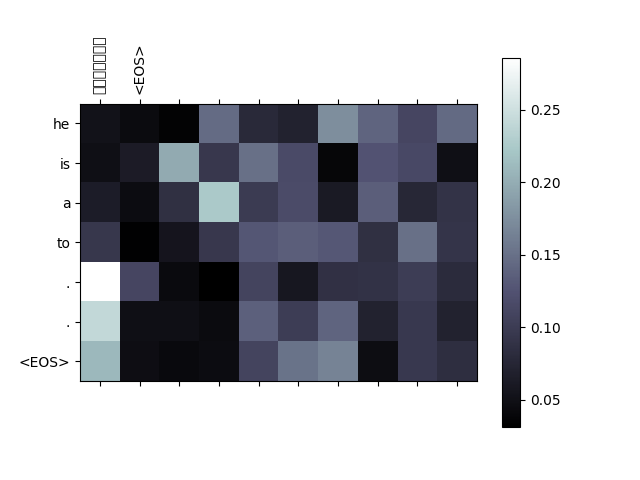
热图:
热图可以简单的理解为协方差矩阵按照颜色和位置绘制的特殊图案,用于表达数据相关度的一个好用的可视化工具
总结 本期博客介绍了循环神经网络系列内容,当然Seq2Seq内容过长,学起来难度不小,所以需要反复复习才可以精通,基础内容也不能拉下,共勉!