环境配置 安装python3.8:https://www.python.org/ftp/python/3.11.0/python-3.11.0-amd64.exe
安装N卡的CUDA和CUDNN:需要安装对应显卡版本,我这里是rtx 3070,所以安装对应版本即可
Pytorch:去官网选择CUDA版本,一定要选择显卡版本,cu后面的三位数字就是cuda版本号
测试环境:
1 2 3 import torchprint (torch.__version__) print (torch.cuda.is_available())
基本叙述 首先,确保你掌握python语言的基础与基本的数学原理:
python基础部分在公众号就已经写过了,所以我就不抄了。
基本的原理可以看:https://blog.minloha.cn/posts/111300e57886172021121307.html
本系列博客的目的是帮助读者了解神经网络的实现原理与代码的写法,基础数学内容和python语法需要自行掌握。当然,涉及到了我就说一下哈~
全连接神经网络 所谓全连接神经网络自然就是基于MP神经元进行的网络结构,每层之间互不干涉,但是层与层之间每个节点都相互连接,同时也有前向传播(预测)和反向传播(学习),这些数学的运算公式可以在:神经网络的实现 一期中看到,那么我们如何用pytorch实现这样的一个神经网络呢?
首先我们需要清楚全连接神经网络(FNN)是做什么的,我们可以把它理解为一种简单的函数拟合器,每次计算的过程输入是一个向量,输出也是一个向量。所以FNN姑且叫他向量计算器,那么最简单的就是线性回归计算(当然非线性也可以)
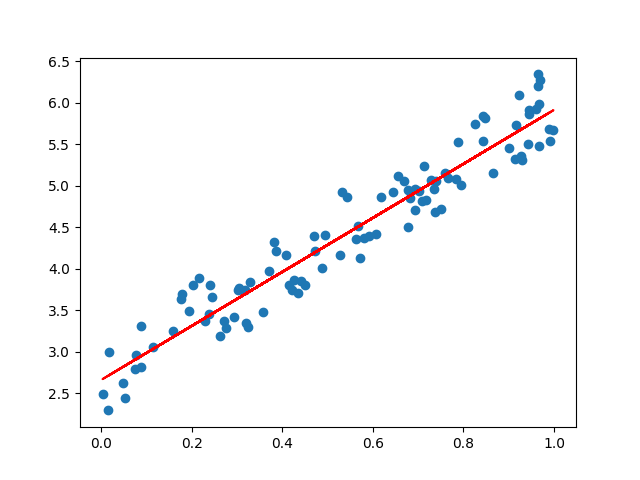
根据单层神经网络可以拟合任意单值连续函数 ,我们可以用一个线性数据生成器当作数据样本,一个单层神经网络就可以:
1 2 3 4 5 6 def generate_data ():100 , 1 )3.3 + 2.2 + torch.rand(100 , 1 )return x, y
这里用到了函数torch.rand,两个参数分别为向量数和向量的秩。同时torch有加减乘除,直接用对应符号即可,对于矩阵点乘就可以用*,而外积得用@符号计算。
如何写一个神经网络?神经网络究竟是什么?
- 一般神经网络可以简单为一种万能函数拟合器,但是每种神经网络都有自己的拟合范围,比如CNN更擅长对矩阵操作,FNN更擅长对向量操作等等
- 当我们掌握一般神经网络结构后,我们可以把它究竟是哪一部分可以实现这种功能给分析出来,比如FNN为什么擅长对向量操作,原因就是他的计算方式决定的
- 掌握神经网络结构的精髓后,我们可以把它当作拼图一样看待,如果你对OpenAI的各种模型有所了解就会发现,他的模型都是将基本结构进行的简单组合,而这也正是大模型的内涵(简单拓扑结构但是庞大的数据量)
使用pytorch的nn.Sequential可以构建一个基本的网络序列,但是为了能够实现拼图一样的思路,我们使用类继承的方式完成:
1 2 3 4 5 6 7 8 9 10 11 12 13 class FNN (nn.Module):def __init__ (self ):super (FNN, self ).__init__()self .layer1 = nn.Linear(1 , 1 )def forward (self, x ):self .layer1(x)return x
如此简单就实现了FNN类,只需要对他实例化即可使用这个模块,当然我们也可以叫他线性拟合器(名字而已,随便叫)
接下来实现训练过程,训练需要用到网络,输入量,理论输出量,更新器(optimizer)和损失函数(loss),损失函数负责计算实际输出和理论输出之间的差距,更新器主要负责训练网络本体:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def train (net, x, y, optimizer, loss ):for i in range (1000 ):if i % 100 == 0 :print ('epoch %d, loss %.4f' % (i, l.item()))return net
常用损失函数 香农熵也是最基本的信息熵,它用于衡量数据的不确定性也相当于一种分散程度
对于两组信息p和q,交叉熵用于衡量这两组信息不确定性的差异,也相当于分散的差异,对于两组不同的分布,可以用交叉熵衡量分布的差异
相对熵也叫KL散度,相对熵是在距离空间上衡量两者距离,KL散度则是衡量不相似性
其中有一个恒等式
Softmax函数(SoftMarginLoss) 其中y对应了不同情况下的的输出值,得出的结果非负且和等于1
优化方法 梯度是高等代数的内容,对于一个多元函数f(x,y,z),他的梯度用$\nabla$表示,计算方法为:
梯度本身就是一种方向导数,所以当梯度最大时,坡度也就最大。梯度下降的表达式为:
其中$\eta$是步长,通过迭代$\theta$就可以实现优化。
根据物理的动量守恒公式,得到函数的最低点。其中梯度的计算公式为:
速度更新是在下滑过程中有摩擦,所谓摩擦实际上是对速度的变化。μ为摩擦,gard就是梯度
权重更新,α是学习率,v为实时的速度。
同理衍生出Adagard,即改变不同位置不同方向上的学习率,δ为稳定用的数值,一般为$10^{-5}$,改变的规则为:
其中的r为梯度的累加值,即:
自适应也有RMSPorp。
最后给出main方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 if __name__ == "__main__" :0.1 )'r-' )
看看效果吧~
1 2 3 4 5 6 7 8 9 10 11
反向传播方法我也复述一下:
正向传播 假设一个感知器有n个输入,激活函数假定为sigmoid(σ)那么我们有:
所以最终输出值的偏导数基于链式法则就是:
根据这个表达式,我们得到的就是反向传播
反向传播 如果我们知道最后的结果以及表达式,基于链式法则,我们可以求出各层的梯度,所以反向传播公式就是:
虽然公式与正向传播相似,但是意义不同
卷积神经网络 这部分其实与计算机视觉有很大关系,神经网络实现的计算机视觉也叫深度视觉,其实卷积神经网络很早很早前就说过了,这里再叙述一遍:
卷积神经网络运用卷积算法计算矩阵之间的乘积,卷积计算对两个矩阵的大小没有严格规定,数学原理可以看:卷积神经网络与傅里叶变换的关系 一个卷积层里面可能有很多个用于计算和学习的卷积核,他们彼此之间有差异,比如处理一个通道可能有三个卷积核,这些卷积核计算的结果各自独立,并不会互相交换数据 卷积层与输入通道有很大关系,比如输入通道有3个(图片的RGB),不同通道同一个位置的卷积核计算结果进行加和,最后得到的输出通道数与每个通道处理的卷积核数量有关,比如RGB三层,每层都有10个卷积核,那么输出通道就是10 池化层会根据池化半径将输出尺寸进行除法取整, 用pytorch实现的话,我用mnist数据集实现,因为数据都是单通道的(灰度图),所以输入通道设置为1即可,那么我们的流程就确定了:
非常简单,对吧~,首先完成第一步:获取训练集和测试集,这里用了torch自带的下载方式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 train_loader = torch.utils.data.DataLoader('data' , train=True , download=True ,0.1307 ,), (0.3081 ,))512 , shuffle=True )'data' , train=False , transform=transforms.Compose([0.1307 ,), (0.3081 ,))256 , shuffle=True )
接下来确定网络形状,mnist每个图片都是28×28的,用NCWH表示就是[b,1,28,28],其中b就是样本数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class CNN (nn.Module):def __init__ (self ):super ().__init__()self .model = nn.Sequential(1 , 32 , 3 , 1 ),2 ),32 , 64 , 3 , 1 ),2 ),64 * 5 * 5 , 128 ),128 , 10 )def forward (self, x ):return self .model(x)
如此一来,我们就有了网络模型,他是一个:
第一层输入尺寸28×28一张,输出26×26共32张特征图 第一层池化,池化半径为2,长宽都除以2并向下取整 第二层输入32通道,尺寸为13×13,输出为64通道,尺寸为11×11 第二层池化,池化半径为2,长宽都除以2并向下取整,最终输出有64通道,每个通道都是5×5 打平层与池化输出参数量有关,因每个通道都是5×5,所以一共是64×5×5个参数,全连接后变成128个参数 最后输出层负责把128变成10个,也就是手写数字(0~9) 训练函数也要有,当然都放在cuda上运行,不然速度有点慢。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ''' :param net: 神经网络 :param train_iter: 训练数据集 :param num_epochs: 训练次数 :param lr: 学习率 :param device: 设备(一般是cuda或者cpu,多个显卡会变成cuda1、cuda2等等) ''' def train_ch6 (net, train_iter, num_epochs, lr, device ):print ("training on" , device)for epoch in range (num_epochs):0.0 , 0.0 , 0 , time.time()for X, y in train_iter:1 ) == y).sum ().cpu().item()0 ]print ('epoch %d, loss %.4f, train acc %.3f, time %.1f sec' 1 , train_l_sum / n, train_acc_sum / n, time.time() - start))
同理,我们还需要一个测试函数计算输出准确率,测试函数和训练函数唯一区别就是不更新梯度:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def test (model, device, test_loader ):eval ()0 0 with torch.no_grad():for data, target in test_loader:'sum' ).item() max (1 , keepdim=True )[1 ] sum ().item() len (test_loader.dataset)print ('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n' .format (len (test_loader.dataset),100. * correct / len (test_loader.dataset)))
最后就是调用这些方法:
1 2 3 4 5 if __name__ == "__main__" :'cuda' if torch.cuda.is_available() else 'cpu' )5 , 0.001 , device)
我们看一下输出:
1 2 3 4 5 6 7 8 training on cuda1 , loss 0.0007 , train acc 0.908 , time 12.3 sec2 , loss 0.0002 , train acc 0.976 , time 14.7 sec3 , loss 0.0001 , train acc 0.984 , time 8.4 sec4 , loss 0.0001 , train acc 0.986 , time 7.9 sec5 , loss 0.0001 , train acc 0.990 , time 11.0 secset : Average loss: -13.8237 , Accuracy: 9885 /10000 (99 %)
可以看到,准确率高达99%,证明我们的网络成功运行了
循环神经网络 RNN实现也非常简单,只需要按照之前说过的定义顺序即可,这里给出RNN的数学原理传送门:https://blog.minloha.cn/posts/172730dca99de52022112710.html
这里我要实现一个时间序列预测(效果非常差)用于展示RNN的结构,一般很少使用到RNN而是使用更为严谨了LSTM或者GRU等等,但是也不能不说,所以就写一下:
1 2 3 4 5 6 7 8 9 10 class RNN (nn.Module):def __init__ (self, input_size, hidden_size, output_size ):super (RNN, self ).__init__()self .net = nn.RNN(input_size, hidden_size, num_layers=1 , batch_first=True )self .fc = nn.Linear(hidden_size, output_size)def forward (self, x ):self .net(x)self .fc(out[:, -1 , :])return out
RNN需要进行两次运算,一次对记忆内容重新处理,一次对输入进行计算,这两个我们可以叫H层和O层,其中H层是对上次输出进行记忆输入,O层是针对此次输入进行计算输出。
其中我们的$z_t$等于如下形式:
而输出有:
反向传播算法BPTT就是根据时间进行反向学习,这当然很简单:
首先我们需要一个损失函数L,我们让损失函数关于前一时刻的输出进行建立关系:
解释一下这个微分,他表达损失函数关于第ij个循环节点的参数的偏微分,因为循环神经网络是有时间关系限制,所以我需要将所有时间的链式法则进行加和,最后就是基本的链式法则表达时刻t节点(i,j)的微分。为了包含进所有记忆体,我们将链式结构在时间上展开:
为了便于表示我们定义一个误差变量,它的计算依然是链式法则,写出对应项即可:
其中E是单位矩阵,负责把激活函数的导数值变成矩阵形式(导数值应为向量),这样我们可以有最终的计算公式:
关于输出过程的迭代可以很容易的计算:
这部分可以去查看我的往期博客:https://blog.minloha.cn/posts/172730dca99de52022112710.html
言归正传,我们再完成数据集处理部分,这里我在github随便找了一个csv文件进行序列预测,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 file = "serial.csv" 0.7 def getData ():1 ])'float32' )max (dataset) - np.min (dataset)list (map (lambda x: x / scalar, dataset))return dataset''' :param dataset 数据集 :param step 预测步长(步长在一个合理的域效果好,不能过大或过小) ''' def create_dataset (dataset, step=2 ):for i in range (len (dataset) - step):return torch.tensor(np.array(dataX)), torch.tensor(np.array(dataY))
然后我们确定一下训练方法,当然和前文叙述过的大同小异,无非就是给网络和训练数据,根据学习率和优化器进行反向传播:
1 2 3 4 5 6 7 8 9 10 11 12 13 def train (net, x, y, optimizer, loss ):for i in range (80 ):if i % 10 == 0 :print ('epoch %d, loss %.4f' % (i, l.item()))
而测试方法自然就用测试集进行预测:
1 2 3 4 5 6 7 8 9 def test (net, x, y, loss ):'real' )'predict' )print ('test loss %.4f' % (l.item()))
然后我们在main方法里把数据集分割一下,按照TRAIN定义的0.7分割训练集和测试集:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 def RNNtry (train_X, train_Y, test_X, test_Y ):1 , 2 , 1 )0.1 )if __name__ == "__main__" :int (len (data_X) * TRAIN) len (data_X) - train_size
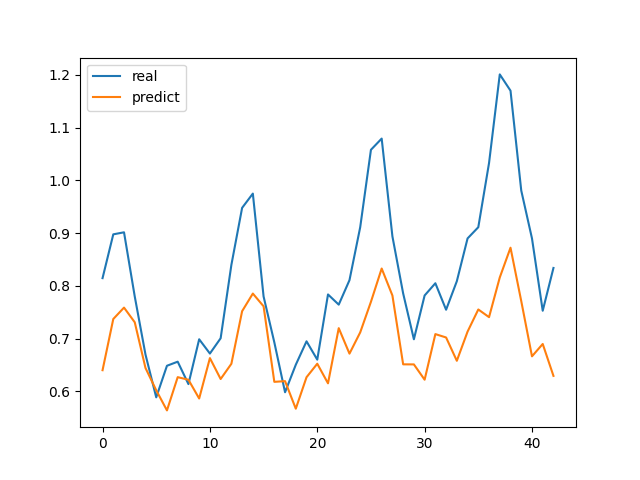
然后我们看看运行效果,查看一下我们的学习效果:
1 2 3 4 5 6 7 8 9 epoch 0, loss 0.0753test loss 0.0102
绘制的图像如图:
从输出数据上我们可以看到损失值在直线降低,而从图像上我们看到测试集的误差不太美观甚至差距有点大了,原因是RNN本身结构的缺陷:
RNN没办法指定遗忘,所以就产生了一个长程依赖问题,学术的说就是长期学习让回忆内容的权重被大量未来数据影响变低了 ,通俗的说就是记得太多学杂了 而这种长程依赖问题就可以用LSTM(长短期记忆网络)或者GRU(门控循环单元)去解决,这个放到下次博客吧~
总结 本期博客内容非常干,读者可以快速学会各种基础神经网络的结构,同时使用了pytorch(不用tensorflow,没有torch写起来容易)实现了全部功能,相信坚持下去一定会有明显进步吧~
本期博客代码开源,开源地址为:https://github.com/iMinloha/TorchPro.git